Updated 20.07.2004. Mail an schatz@askos.de
Aus Anlaß 20 Jahre PC-Programmierung: Wie kriege ich Hauptspeicher?Meiner lieben Ursl gewidmet Beim Wort "Hauptspeicher" denken viele sicher an RAM. Die RAM-Zahl prangt einem in jeder PC-Zeitungsbeilage entgegen: Je mehr, desto besser, mindestens MB, mindestens dreistellig und Speicher ist etwas, was manchmal teuerer, meistens aber immer billiger wird. Aus Sicht des Programmierers ist Hauptspeicher das Papier, auf dem er schreibt, das Wasser, in dem er schwimmt. Hauptspeicher ist der elektronische Speicher für Programme und Daten. Heute wird er vom Programmierer nur noch selten wahr genommen. Aber das war nicht immer so. Hier einige Erinnerungen und Gedanken an die letzten 20 Jahre "Speicher und PC". Das ist ein Text, der in meiner Freizeit entstanden ist. Ich habe mich zwar bemüht, möglichst genau zu sein, aber mancher wird sicher hier und da noch über kleinere Fehler stolpern. Andere Fehler entstehen durch Verkürzungen, da dies ein Text zum Schmökern, kein Nachschlagewerk werden sollte. Insbesondere bin ich bei den Adressierungstechniken des 8088 und beim A20-Gate nicht in die Details gegangen. Natürlich ist dieser Text auch durch meinen spezifischen Programmiererhintergrund beschränkt, der eng mit der Firma Borland verknüpft ist. Beispiele für Sprachen und Entwicklungstools, die ich nie benutzt habe, werden sich hier nicht finden. Für Hinweise auf Fehler bin ich sehr dankbar. Über Berichte eigener Erfahrungen mit dem "Speicherabenteuer" PC würde ich mich sehr freuen! Inhalt
EinleitungHauptspeicher ist der elektronische Speicher für Programme und Daten. Ein Programm muss im Hauptspeicher liegen, damit es ausgeführt werden kann und Daten müssen im Hauptspeicher liegen, wenn sie das Programm benutzen soll. Am einfachsten macht man sich dies an einem Editor-Programm klar. Ein Editor ist ein Programm zum Schreiben von Texten ohne Layout. Die Date, mit der der Editor operiert, ist der Text. Damit Text bearbeitet werden kann, muss er in den Hauptspeicher geladen werden. Nun gibt es relativ grosse Texte, z.B. wenn Messdaten in Textformat (ASCII-Format) abgespeichert werden. Da kann es selbst heute noch passieren, dass der Editor nach langer Ladezeit meldet: "Kein Hauptspeicher mehr". Oder er stürzt gleich ab. Für den Programmierer ist das Ansprechen und Organisieren des Hauptspeichers prinzipiell ein alltägliches Geschäft. Man muss ja auch nicht lange überlegen, WIE man ein Blatt Papier beschreibt. Deklarieren, Reservieren, Initialisieren und los geht's. Oft ist es sogar noch einfacher: In der Programmiersprache BASIC muss man im Zweifelsfall gar nichts tun. Man nutzt einfach Namen, meint damit Variablen und BASIC ordnet den Hauptspeicher zu. Wieso ein Artikel zu diesem Thema? Ein Besonderes der PC-Geschichte ist: Fast immer in den letzten 20 Jahren, wenn man auf einem PC ein größeres Projekt programmierte, rumste man unweigerlich gegen eine Fehlermeldung: "Kein Hauptspeicher mehr" - obwohl noch Massen davon vorhanden waren. Immer dann, wenn man gerade richtig am Schreiben und Entwickeln war, sagte einem der PC: "So, schluss jetzt, kein Platz mehr!". Man muss sich das mal als Romanschreiber vorstellen: Man ist gerade richtig in Fahrt, kommt an die richtig spannende Stelle und mitten drin stellt man fest, dass 400 der 500 Blatt Papier, die man sich vorher besorgt hat, mit einer Kunststoffbeschichtung versehen sind, die nicht beschreibbar ist. Warum konnte sich so eine Maschine durchsetzen? Mac-, Atari-, Amiga- und Unix-Programmierer können hier nur den Kopf schütteln. Ich habe selbst jahrelang auf dem Amiga programmiert und wenn dort der rote Kasten "Heap Overflow" auftauchte, dann war der Speicher wirklich aus, da half nur der Gang zum Händler, um sich ein Erweiterungsmodul zu kaufen. |
|
Screenshot des Spiels "Tetris", Urversion von Academy Soft Moskau 1986. Größe: Eine com-Datei mit 24K. Voraussetzungen: IBM PC 4.77 MHz, 64K RAM. Grafikkarte ist nicht erforderlich. Nun, meine vielleicht etwas gewagte These ist: Wahrscheinlich hat sich der PC gerade WEGEN dieses Problems durchgesetzt. Genauer gesagt: Wegen seiner restriktiven Kompatibilitätspolitik. Sie sorgte einerseits dafür, dass heute viele 20 Jahre alten Programme noch auf den neuesten Boliden laufen (z.B. Tetris in Urform!). Sie brachte andererseits unter anderem genau dieses Speicherproblem mit sich. Vielleicht war es nur diese restriktiven Kompatibilitätspolitik, die dem PC die Durchsetzung vor allen anderen Mikrocomputer-Typen brachte. Die furiosen Kunstgriffe, das Unvereinbare zu vereinen, Hardwareerweiterung und 100%-Kompatibilität zu verbinden, begleiteten den PC von Anfang an, machten ihn zu einem wundersamen Chamäleon, technik-ästhetisch zu einer Katastrophe, verliehen ihm aber aus der Sicht des Programmierers ein Abenteuerflair und bildeten mit der Zeit lebende Geschichte. Wenn ich heute als Programmierer gegen einen "kein Hauptspeicher"-Fehler rumpse, obgleich ich nicht einmal 5% des verfügbaren Speichers belege, dann begleitet den Ärger ein nostalgisches Lächeln und die Feststellung, dass Programmieren nur halb so schön wäre, müßte ich diese Kollisionen mit der PC-Geschichte entbehren. 1980 - der Ur-PCVersetzen wir uns in die Zeit, als das Design des PC's festgelegt wurde.
IBM war Marktführer im Bereich Grossrechner (und ist es heute
noch).
Der PC war als Versuchsballon geplant, um ein Einstiegspotential in
den
Mikrocomputermarkt aufzubauen. Im Vergleich zu Grossrechnern war ein
PC -
wie auch immer - in Bezug auf professionelle Anwendungen ein Spielzeug.
Grossrechnerersatz für den daheim arbeitenden Ingenieur, Textverarbeitungsmaschine,
grosser, programmierbarer Taschenrechner.
Zu diesem Zeitpunkt gab es auf dem PC-Markt:
|

|
IBM 5100 von 1976, einer der ersten Mikrocomputer mit Textanzeige. Grundausbau: 64x16-Zeichen-Display, 16K, BASIC oder APL, ca. 9000$ Der IBM PC war nicht wirklich der erste Mikrocomputer von IBM. Vorher hatte es eine ganze Reihe von Entwicklungen seit 1975 gegeben, die aber alle reine IBM-Eigenentwicklungen ohne Bestandteile fremder Hersteller und alle sehr teuer waren und alle von den Verkaufszahlen das Kleinserienstadium nie überschritten. Daran hatte IBM erkannt: Die Hardwareleistung allein ist kaum interessant. Wichtig sind Preis und Kompatibilität. IBM wollte nun mit seinem PC
Der PC sollte der Universal-Mikro für ein breites Spektrum und Anwender sein. Sowohl der gelegentliche Programmierer, der maximal 50 Zeilen BASIC schreibt, als auch der Leistungsanwender, der eine kleine Firmendatenbank damit betreiben wollte und mit den 64K längst nicht zurecht kam. Daher entschied sich IBM für einen Intel 8088-Prozessor, der genau diesen Spagat ausführen konnte. Da viele spätere Probleme mit der speziellen Adress-Architektur dieses Prozessors - dem Urvater aller PC-Prozessoren - zu tun haben, möchte ich die folgenden Abschnitte dem Thema "Adressierung" widmen. AdressgrenzenHauptspeicher ist eine Menge von elektronischen Speicherbits, angeordnet in Bytes zu je 8 Bit. Der Prozessor spricht jedes Byte mit einer Zahl an. Das Byte Nr. 0 mit 0, das Byte Nr. 1 mit 1 usw. Diese Zahl ist seine Adresse. Hat der Hauptspeicher 1024 Bytes, so gehen die Adressen von 0 bis 1023. Die Speicherbytes werden über die Adressleitungen angesprochen, den s.g. Adressbus, der die einzelnen Bestandteilen des PC's (Prozessor, Speicher, Controler usw.) verbindet. Jede Leitung kann 1 Bit einer Speicheradresse darstellen. Hat ein Adressbus drei Leitungen, ist er 3 Bit breit und kann 2^3 = 2 hoch 3 = 8 Bytes adressieren. Hat er 10 Bit, dann 2 ^ 10 = 1024 Bytes. Jedes zusätzliche Bit verdoppelt also die Anzahl möglicher Adresssen. Die 1980 üblichen Prozessoren in Mikrocomputern hatten 16-bit breite Adressbusse, was 2 ^ 16 = 65536 = 64K Bytes ermöglichte. Warum fügte man eigentlich nicht einfach eine 17. Leitung dazu, als der Platz knapp wurde? Und dann eine 18. usw.? Wo liegt eigentlich das Problem? Ein Prozessor ist ein Elektronik-Chip mit vielen Beinchen. Ein damaliger
8-Bit-Prozessor hatte ca. 30. Bank SwitchingEs war nicht so, dass es nicht auch Lösungen gegeben hätte. Schon für einen der allerersten "PC", der Apple II, basierend auf einem Prozessor mit 16 Bit Adressraum, wurde eine 128K-Karte angeboten - der Nachfolger Apple III kam sogar von Haus aus mit soviel Speicher zum Kunden, obwohl auch er auf dem MCS 6502 aufbaute. Die Lösungen liefen mehr oder weniger alle auf das Verfahren des "Bank Switchings" hinaus. Ein zusätzlicher Chip schaltete bei diesem Verfahren den logischen Adressraum oder Teile davon auf andere Speicherbausteine um. Nehmen wir an, ein Computer mit 16 Bit Adressraum ist mit 96K RAM ausgestattet. Das sind dann 32K "zuviel". Der Bank Switch kann nun wahlweise eine von zwei 32K Banks in die oberen 32K des Adressraums einblenden, während die unteren 32K fix bleiben. Dieses Verfahren wurde auf verschiedene Art genutzt. Beim berühmten C64 konnten so 8K des 20K-ROM gegen 8K weitere RAM eingetauscht werden, da der C64 mit echten 64K RAM bestückt war. Beim CPC464/664 betrug der benötigte Adressraum 64K RAM plus 32K ROM. Wenn das ganze ROM eingeblendet war, hätten dem Programmierer nur noch weniger als 30K freier Speicherplatz zur Verfügung gestanden. Tatsächlich hatte er 42K, da ein Teil des ROMs per Bank Switching eingeblendet wurde. Die 128K-Boliden der späten 8-Bit-Zeit konnten die zweite 64K-Bank grundsätzlich nur über Bank Switching ansprechen - entweder explizit, wie beim CPC6128 oder implizit, wie beim C128, was letzteren zum Schleichrechner werden ließ. Was praktisch klingt, war nur eingeschränkt nutzbar. Der Programmierer mußte sein Hauptspeichermanagement gut organisieren: Was kommt in die eine, was kommt in die andere Bank? Was tun, wenn die eine voll ist, die andere noch nicht, etwas aber eigentlich in die erste Bank gehört? Es gab nur zwei Wege: Entweder ein ausgeklügeltes Managementprogramm benutzen, das aber selbst wiederum Speicher und Rechenzeit frass oder das Management selbst programmieren, was viel Aufwand bedeutete. In jedem Fall musste unter Umständen viel hin- und hergespeichert werden, was Zeit kostete - vergleichbar zu heutigen PCs, wenn sie "swappen", d.h. zwischen Hauptspeicher und Festplatte Hauptspeicher- inhalte austauschen. Der 8088 des Ur-PCIn diese Situation hinein kam der 8088 von Intel. Grundlegend an seiner Adresstechnik war die Segmentierung in 64K-Blöcke. Jede Adresse kann aus zwei Teilen bestehen: Segmentnummer (2 Bytes) und Adresse innerhalb des Segments, (2 Bytes) der s.g. Offset. Kompliziert, aber es war dadurch möglich, daß eine Adresse nicht 4 Bytes haben MUSSTE. Es können auch zwei Bytes genügen, wenn klar ist, um welches Segment es sich handelt. Damit das klar ist, kann man dem 8088/86 vier Segmentnamen übergeben. Und ihm sagen: "Arbeite ab jetzt mit Segment Nr. 2" - Bank Switching läßt grüßen. Damit ergeben sich drei Hauptspeichermanagement-Modelle:
Besonders Modell 2 war interessant, da es für die CP/M-Programmportierung auf den PC nur wenige Eingriffe erforderte, um mindestens 128K Speicherplatz zur Verfügung stellen zu können - ein eindeutiger Vorteil des PC gegenüber den Konkurrenzsystemen. Von 16K bis 1 MBKommen wir zurück zur Programmierersicht. Die oben angeführten Aspekte brachten manche Merkwürdigkeit mit sich. Kaufte man um 1981 den Ur-PC, konnte man ihn sich theoretisch mit 1 MB RAM bestellen. (Wegen eines Elektronikfehlers tatsächlich nur mit 576K), da der 8088/86 16 Segmente adressieren konnte (der physische Adressbus war 20 Bit breit: 16+4). Schon 512K kosteten ca. 4000 DM und in Zeiten, in denen ein Programm mit 30K als groß galt, erschien dies eher absurd. Der Ur-PC wurde mit BASIC im ROM ausgeliefert und dieses BASIC arbeitete nach Modell 2.: Für Userdaten, d.h. das BASIC-Programm und die Variablen standen knapp 64K zur Verfügung. Das war vergleichsweise viel. Die kleinste PC-Version kam mit 16K RAM auf den Markt, was für die eingangs zitierten 50 BASIC-Zeilen genügte. Aber wenn man 4000 DM für RAM ausgegeben hatte, war es bitter, nur 1/8 des teueren RAMs zur Verfügung zu haben! Es dauerte eine geraume Zeit, bis Programme wie dBase, Word usw. auf den Markt kamen, die mit Modell 3 arbeiteten. Und es dauerte bis 1987, bis Turbo Pascal 4.0 der Firma Borland die 64K-Grenze sprengte und echte .exe-Binaries ermöglichte. MS-DOS und die 640K-GrenzeWas auch immer über MS-DOS und PCs geschrieben wurde, eines ist klar: 1980 sollte der PC eine CP/M-Maschine werden. Nur kam die CP/M-Portierung nicht so zustande, daß CP/M 1981 mit dem ersten PC hätte mitausgeliefert werden können. Der PC brauchte aber ein eigenes Betriebssystem. Und dies war MS-DOS. Sehr CP/M-ähnlich, aber von Anfang an für eine 4-Byte-Adressierung ausgelegt.Da klar war, daß ein PC, den IBM herausbringt, wichtig sein wird, war es für die großen Softwarehersteller von Anfang an wichtig, ihre Produkte für den IBM PC verfügbar zu haben. Aufgrund der Segmentierung und der CP/M-Ähnlichkeit von MS-DOS war die Portierung auch kein großer Aufwand. Wenngleich die ersten Versionen der jeweiligen Programme aus dem PC kaum mehr herausholten als aus einer CP/M-Maschine. Bei 128K Grundausstattung für PCs bis 1984 war dies kein größeres Problem. Ergo: Weil der Druck zur Portierung unterschätzt, MS-DOS relativ primitiv und die Portierung dadurch einfach war, warteten die Herstellter nicht auf CP/M, der Zug fuhr ab und die PC-Welt war MS-DOS. Wahrscheinlich war es ein Glücksfall, daß IBM und Microsoft die Rolle von MS-DOS völlig falsch eingeschätzt hatten und ihm ein Minimum an Leistungsfähigkeit zukommen ließen. Dadurch war ein DOS-Rechner einfach schnell. Für Dinge wie Multitasking, Piping usw. interessierte sich zu dieser Zeit unter den PC-Usern ohnehin keine Sau. Worin bestand nun die ominöse 640K-Grenze? Nun, wie David Bradley, einer der Systemdesigner des Ur-PCs in einem Artikel in der c't' 10/90, S. 34 erzählt, überlegte man, den Adressraums des PC's in folgende Bereiche aufzuteilen:
Und man setzte die Überlegung in die Tat um. Auf den ersten Blick erschien diese Aufteilung sinnvoll: 640K war damals ungefähr genauso viel Platz wie 2002 40 GB, ca. 60% der maximal adressierbaren 64 GB eines Pentium III/4. Es war kaum vorstellbar, dass man einmal mehr brauchen würde. Auf der anderen Seite gab es keinen Zwang, die Reihenfolge so festzulegen. Man hätte das Conventional Memory auch obenauf packen können. Man hätte vor allem aber die Grenzen des Adressraums nicht fixieren müssen. Eine Tabelle an fixer Adresse mit den Segmenten der reservierten Bereiche hätte genügt und man hätte viel mehr Flexibilität gehabt. Den geregelten Hauptspeicherzugriff hätte dies kaum verlangsamt. Schliesslich waren alle Programme in der DOS-Äria auf Operationen innerhalb von Segmenten orientiert, die Neuzutritt zu einem weiteren Segment geschah nur relativ selten. Die Speicheraufteilung und die fehlende Allocation Table war also der erste Pferdefuss. Auf diese Weise konnte kein Assemblerprogrammierer auf den Bereich oberhalb 640K, die s.g. UMA (Upper Memory Area) zugreifen, ohne das Risiko einzugehen, in die Ports einer Adapterkarte (z.B. einer Netzwerkkarte) oder in einen Grafikspeicher reinzuschreiben. Der andere Pferdefuss war DOS. DOS hätte durchaus es übernehmen können, die fehlende Allocation Table zu ersetzen. Dafür hätten allerdings alle Hardware-Erweiterungen bei DOS angemeldet werden müssen (so, wie das heute bei Windows geschieht). So eine Anstrengung hat es nie gegeben, vermutlich deshalb, weil mit zusätzlichen 128K bis 192K das SPeicherproblem unterhalb der 1 MB-Grenze auch nicht gelöst worden wäre. Ab 1990 gab es von seiten der Firma Digital Research und von Herstellern von Memory Extendern (siehe unten) eine etwas andere Lösung: Zwar war die UMA für Daten und Programme immer noch tabu, aber Treiber und die DOS-residenten Dateien konnten dorthin verlagert werden. 1992 zog dann MS-DOS nach, indem es diese Techniken lizensierte und DOS 5.0 befügte. Insofern stelle ich die These auf: Es hat nie ein 640K-Problem gegeben. Vielmehr ein 1 MB-Problem. Und das war weder mit einer Systemerweiterung noch mit einem besseren DOS zu lösen. Die 1 MB-GrenzeDass es unter DOS eine 1 MB-Grenze gab, ist nicht so logisch, wie es sich vielleicht zunächst anhört. Die 1 MB-Grenze war alles andere als unvermeidlich, sondern hängt letztendlich von einer recht willkürlichen Entscheidung ab. Ich kenne die Entscheidung und will sie gleich darstellen, leider weiss ich jedoch nicht sicher, wer sie letztendlich getroffen hat. Vermutlich waren es die Prozessor-Designer bei Intel. Fassen wir nochmals zusammen, was wir im Abschnitt "Adressgrenzen" besprochen haben:
Wenn man nun "16" durch "20" ersetzt, hat man den Fall des 8086/88 und damit die 1 MB-Grenze. Denkt man. Stimmt aber nicht. Denn für eine 20-Bit-Adresse braucht man mindestens 3 Bytes. Das heisst, die logische Adressbreite eröffnet einen logischen Adressraum von 16 MB. Und beim 8086/88 ist die logische Adressbreite nicht nur 3 Bytes, sondern, wie wir gerade gelernt haben, 4 Bytes. 2 Bytes für den Offset und 2 Bytes für die Segmentangabe. Das heisst, man hätte im logischen Adressraum Platz für 64K Segmente a 64K, also für 4 GB. Wo war eigentlich das Problem und wo soll hier eine 1-MB-Grenze sein? Nun gut, beim 8086/88 entsprach nur den ersten 16 Segmenten eine physikalische Adresse. Aber beim 80286 hätte es den Protected Mode nicht gebraucht. Programme hätten unter DOS einfach bei Bedarf Segment 17 bis 256 mitnutzen können. Worin lag das Problem? Das Problem lag darin, dass aus ziemlich unerfindlichen Gründen sich jemand dazu entschieden hatte, dass für die Segmentnumerierung nicht die ganzen 2 Bytes genutzt wurden, sondern nur die oberen 4 Bits. Die unteren 12 Bits waren redundant. Falls sie gesetzt waren, wurden sie zu den oberen 12 Bits der Offsetadresse addiert. Das, was ich jetzt nicht weiss, ist, ob die Übersetzung der logischen in die physikalische Adresse im Prozessor selbst geschieht oder ob dies im BIOS erledigt wird. Vermutlich im Prozessor selbst, ansonsten hätten die BIOS-Hersteller vermutlich bald 16-MB-kompatible Versionen ihrer Produkte herausgebracht und Intel hätte sich den Protected Mode sparen können. Eine misslichere Entscheidung als diese, die unteren 12 Bits der beiden Segmentbytes praktisch wegzuwerfen, hat es in der PC-Geschichte wohl nicht gegeben. Die Folgen für die PC-Entwicklung waren zwar im Grossen gering, aber im Kleinen ärgerlich: Wieviel Programme konnten nicht so geschrieben werden, wie sie ihr Schöpfer schreiben wollte, weil er zwar vor einem 4-MB-PC sass, aber nur 1 MB zur Verfügung hatte? Der 640K-KampfDie Zeit blieb nicht stehen und nach 1987, als eine Textverarbeitung mit Silbentrennung, Thesaurus und Doppelseitenformatierung aufwarten musste, wurde es in den 640K langsam eng. Zumal 1986 der Atari ST mit vollständig adressierbaren 1 MB, aber für die Hälfte des Geldes daherkam. Auch für die Anwendungsprogrammierer wurde der Hauptspeicher langsam knapper als ursprünglich erwartet. Passte bei Turbo Pascal 1.0 noch Editor, Compiler und Linker samt von denen benötigten Arbeitsspeicher in 40K, so daß 24K für Anwendungsprogramme übrig blieb (Ihnen erscheint das wenig? Dann schreiben Sie erstmal ein 20K langes Programm!), so wuchsen die Ansprüche schnell. Ist ja auch klar: Insgesamt sind bei der integrierten Programmentwicklung 16 Speicherfresser am Werk:
Braucht jeder dieser Fresser im Schnitt 30K, sind 480K weg. Mit dem Aufkommen der Festplatten wurde die Situation etwas gelindert. Daten konnten relativ schnell schnell auf die Platte geswappt werden. (Das ging schon mit einem einfachen 8088 und Random-Access-Zugriff.) Aber das erhöhte den Programmieraufwand und verringerte die Arbeitsgeschwindigkeit wesentlich. Das Nächste waren Overlay-Techniken. Hier versuchte man, Teile des Programms auf die Festplatte zu swappen.BASIC-Programmierer kannten diese Technik schon. Den Befehl "Merge" zum Nachladen von Programmteilen gab es schon bei den frühen Homecomputern. Aber der Programmierer muss so selbst organisieren, was wann gemergt wird. In den strukturierten Programmiersprachen C und Pascal greift man beim Programmieren auf Bibliotheken zurück. Man hatte nun die Möglichkeit, diese Bibliotheken als "Overlay" zu deklarieren: Es wurde zur Laufzeit immer nur der Code geladen, der gerade benötigt wurde. Kam man damit nicht weiter, blieb nichts übrig, als auf den Komfort einer integrierten Entwicklungsoberfläche zu verzichten und jeden Schritt wieder von Hand zu machen: Source abspeichern, Editor beenden, Compiler laden, compilieren, Linker laden, linken, Debugger laden, debuggen, Fehlerzeile aufschreiben, Debugger beenden, Editor laden, Programm verbessern, abspeichern ... Borland verbesserte seine IDE weiter, indem sie die IDE selbst in Overlay-Technik programmierten: Beim Kompilieren wurde der Editor ausgelagert, vor dem Linken wurde der Compiler aus dem Speicher entfernt usw. Das war einerseits angenehm, raubte einem andererseits den Ausweg, durch Verlassen der IDE Speicherplatz zu sparen. Das brachte dann schlicht nichts mehr. Der IBM ATMit dem IBM AT kam der Intel 80286. Dieser hatte 24 Adressbusleitungen, was die Adressierung von 256 Segmenten ermöglichte - 16 MB. Ausweg aus der Speicherkrise? Keineswegs. Um seine Prozessorverbesserungen nicht mit der bisherigen Software kollidieren zu lassen, entschied sich Intel, fast alle Verbesserungen nur in einem neuen Modus verfügbar zu machen: Dem "Protected Mode". Der alte 8086/88-Mode hieß nun "Real Mode". Hintergrund dieses Bruchs zum alten 8086 war die Sackgasse, in die das damalige Lieblingskind von Intel, der iAPX-432, gekommen war. Ein waschechter 32-Bitter mit allen Schikanen, der eigentlich für die grosse Mikrocomputerzukunft ersehen war. Allein, das Provisorium 8086, das allein und ausschliesslich als CP/M-gestützte Überbrückung gedacht war, war so erfolgreich, dass vom AIX kaum jemand Kenntnis nahm. Und so entschied sich Intel, viel der Entwicklungsarbeit für den iAPX-432 via Protected Mode in den 80286 einzuschleussen. Intel hatte wohl die Hoffnung, dass nach und nach die Softwarehersteller Protected Mode-Programme anbieten würden. Das ging aber nicht, solange MS DOS Real Mode blieb. Und MS-DOS blieb Real-Mode, damit die alten Programme noch liefen. So kauften die Leute AT's für viel Geld, aber fast der einzige Vorteil war der um 30% höhere Prozessortakt. Microsoft machte einen ernsthaften Versuch, das schon 1980 herausgebrachte SCO-Xenix, eine abgespeckte Unix-Variante, mit dem AT zu etablieren. Doch die Softwarehersteller zogen nicht mit, da Portierungen auf Xenix sehr aufwendig waren. So schöne Tricksereien, wie Ports direkt zu adressieren, wäre gar nicht möglich gewesen. Und die Leute kauften AT's und Real-Mode- Software, solange es nichts anderes gab. Was ist Protected Mode?Man muss sich unter dem Protected Mode nicht eine komplett andere CPU vorstellen. Vielmehr arbeitet die CPU weithingehend mit den gleichen Registern und Befehlen wie im Real Mode, so dass ein Real Mode Programm prinzipiell auch im Protected Mode laufen würde. Der Unterschied liegt nur in der Adressierung. Intel beabsichtigte, mit dem Protected Mode nicht einfach den Adressbus zu verbreitern, sondern grundsätzlich die Adressierungstechnik zu modernisieren: Es sollte möglich sein, geschützte Adressräume einzuführen. Daher der Name "protected". Sobald also ein Programm über ein Segment hinaus adressiert (eine s.g. FAR-Adressierung), funktioniert im PM alles anders als im RM. Allerdings funktioniert auch schon innerhalb der 64K-Grenze etwas anders: Die Ansteuerung des BIOS. Der Grund ist ziemlich kompliziert und kann hier bei Dr. Dobbs nachgelesen werden.. Dies führt dazu, dass eine simple Textausgabe am Bildschirm anderen Maschinencode braucht wie im Real Mode. Adressierung im Protected ModeDie ersten (hohen) 16 Bit einer logischen PM-Adresse haben eine komplett andere Bedeutung als im RM. Sie sind ein Zeiger auf einen Eintrag in der s.g. Descriptor Table. Ein Deskriptor (also solch ein Tabelleneintrag) enthält die physikalische Adresse des Segments - und seine Länge. Im PM sind Segmente keineswegs immer 64K gross. Sie können auch kleiner sein - sogar nur lediglich ein Byte gross. Wenn eine PM-Adresse also 0010:0008 heisst, dann bedeutet dies keineswegs eine Adresse ganz am Anfang im Speicher. Sondern 0010 ist der zweite Eintrag in einer Desciptor Table. Und dort steht die eigentliche Basisadresse des Segments, z.B. FA0000. Dann kommt noch die Offset-Adresse dazu und wir haben die entgültige physikalische Adresse, nämlich FA0008. 0010 nennt man auch den "Selektor". Er verweist auf den zweiten Deskriptor in der Desciptor Table, da jeder Deskiptor 8 Bytes lang ist. 0008 verweist also auf den ersten, 0010 auf den zweiten, 0018 auf den dritten Deskriptor usw. Es gibt allerdings aufgrund der "Protected"-Idee nicht nur eine Deskriptorentabelle, sondern deren viele. Jede Task sieht dabei immer zwei: Die Global Descriptor Table (GDT) und eine Local Descriptor Table (LDT). Die GDT enthält Segmente, auf die alle Tasks zugreifen dürfen. Die LDT enthält Segmente, auf die nur der spezifische Task zugreifen darf. Auf diese Art und Weise behält die CPU die Kontrolle über Speicherzugriffe. Kommt ein Maschinenprogramm ins Schleudern und führt Nonsense-Code aus, dann wird es früher oder später Bytes als Selektoren interpretieren, die auf verbotene Deskriptoren verweisen - was die CPU dazu veranlasst, "Feueralarm" zu geben - der berühmte "Segment Default Error" beim Absturz eines 16-Bit-Windows-Programms. Weiter ging's meist im Real Mode...Die ersten, die vom Protected Mode ausserhalb von Xenix profitierten, waren diesmal die Programmierer, da Compile?r und Linker keine BIOS- Zugriffe brauchten. Daher konnten hier bald Protected Mode-Versionen angeboten werden - als Kommandozeilen-Programme. Das brachte zumindest den Vorteil, dass man nun Binaries mit vollen 600K schreiben konnte, da es während der Compilation, bzw. während dem Linken, bei dem jeweils zwei Versionen des Programms im Speicher liegen müssen, keine 640K-Grenze mehr gab. Das Binary selbst arbeitete weiterhin im Real Mode. Mithin war die Grenze für Binaries auf ca. 600K angehoben. Wie aber sah es mit dem Variablenspeicher aus? Man muß sich vor Augen halten, daß der AT 1984 auf den Markt kam. Erst 1987 brachte Borland mit Turbo Pascal 4.0 eine erste Programmiersprache für "Normalprogrammierer", mit der man die vollen 640K als Variablenspeicher ansprechen konnte. Und erst 1990 erblickte mit DOS 4.0 eine Möglichkeiten das Licht der Welt, auf AT's über diese Grenze hinauszukommen - zu einer Zeit, in der 386-PCs nicht nur schon käuflich, sondern in der SX-Version schon unter 5000 DM erhältlich und erschwinglich waren. Sehr viel mehr Speicher wurde durch Ramdrive.sys verfügbar. Dieser Treiber schaffte einen besonderen Zugang zum Speicherbereich oberhalb der 1 MB-Grenze. Dieser Bereich nenne ich hier AOM-Bereich ("Above One MB"), um Mißverständnisse mit den später einzuführenden Begriffen "Expanded Memory" und "Extended Memory" zu vermeiden. Ramdrive.sys simuliert einen zusätzlichen Datenträger, speichert dessen Inhalt aber im RAM und zwar im AOM-Bereich. Der Datenzugriff ist dadurch wesentlich schneller, als auf einen echten Datenträger, aber natürlich immer noch viel langsamer als ein direkter RAM-Zugriff. C++-Klasse, die man dazu benutzen kann, Hauptspeicher auf der RAM-Disk zu verwalten. EMSMit LIM, EMS, XMS, VCPI und DPMI betreten wir ein wirklich verworrenes Kapitel der PC-Geschichte, das sich wiederum um die eigentlich so einfache Frage dreht: Wie bekomme ich den Speicher, den ich eigentlich schon habe? Ein Versuch, am Anfang die Verwirrung ein bisschen zu begrenzen...
Zurück zu EMSFassen wir noch einmal die Frühzeit des PC's, diesmal im Jahr 1984, ins Auge. Ein Jahr, nachdem der PC im europäischen Markt eingeführt wurde, dasselbe Jahr, in dem IBM den PC AT mit Intel 80286 (wir kommen noch später darauf) für mehr als 20.000 DM vorstellte, (ausgerüstet mit 512K Speicher), hatten die meisten PC's eine Speicherausrüstung von 64K oder 128K und der Programmierer-Horizont orientierte sich, wie weiter oben schon dargestellt, an CP/M und BASIC-Programmen. Der nutzbare Adressbereich umfasste, wie wir jetzt wissen, den Bereich 0 bis 640K, das s.g. Conventional Memory, und erschien so unerschöpflich, wie im Jahr 2002 4 GB Adressraum. (Und es kostete mindestens genausoviel, auf 640K aufzurüsten, wie es heute kostet, auf 4 GB aufzurüsten...). Expanded Memory und TabellenkalkulationenFirmen und Behörden orientierten sich damals (wie heute) allerdings nicht an dem, was es an üblicher Technik gab, sondern an der Grösse des Problems, dass es für sie zu lösen galt. So erwies sich die Tabellenkalkulation als ein sehr nützliches Werkzeug für Kalkulationen - auch und gerade mit sehr vielen Daten. So kamen auch in den frühen 80er-Jahren schnell Anwendungsfälle für Tabellen mit einigen tausend Zeilen und mehr als hundert Spalten zustande, vor allem, weil es eine Verknüpfung zu Datenbanken, wie sie heute möglich ist, in den frühen Tabellenkalkulationen noch nicht gab. Nehmen wir an, eine Tabellenzelle benötigt 16 Bytes. Die Tabelle hat 256 Spalten. Dann benötigt eine Zeile 4K. Hat man 512K freien Speicher zur Verfügung, ist bei 128 Zeilen Schluss. Für eine Firma, die komplexe Kalkulationen bezogen auf 1000 Beschäftigte oder Artikel oder andere Einheiten durchführen muss, viel zu wenig. Die "Killer"-Applikation in diesem Bereich zu dieser Zeit war Lotus 1-2-3. Lotus 1-2-3 hatte relativ grosszügige Beschränkungen der Grösse der Tabelle. Also entstand sehr schnell der Wunsch, solche Tabellen hauptspeicherseitig auch realisieren zu können. Above BoardsSchon früh brachten Hersteller daher Speicherweiterung-Boards für den IBM PC für Preise von einigen Tausend Dollar auf den Markt. Alle funktionierten via Bank Switching. Die Ansteuerung war aber nicht genormt. Daher hätte Lotus für jeden Board-Hersteller einen neuen Treiber generieren müssen. Das war indiskutabel. Somit setzen sich Lotus, Intel und Microsoft 1983 zusammen und vereinbarten einen Bank-Switching-Standard für den IBM PC, den s.g. "Expanded Memory Standard", EMS, der 1984 verabschiedet wurde. Witzigerweise im gleichen Jahr, als der IBM AT herauskam, dessen 80286-Prozessor ohne Bank-Switching 16 MB RAM adressieren konnte. Aber die praktische Nutzung dieses Features war aus mehreren Gründen Zukunftsmusik für die derzeitigen Lotus- und Framework-Nutzer: Die Anschaffung eines IBM AT plus dem benötigten Speicher war allemal teurer als die Anschaffung lediglich des benötigten Speichers. Intel brachte noch im gleichen Jahr das erste EMS-Erweiterungsboard heraus. Es hatte neben dem Speicher gleich einen Memory-Controller, der das Bank-Switching verwaltete. Kurze Zeit später zogen die anderen RAM-Kartenhersteller nach: Alle Speichererweiterungskarten waren in der Folgezeit EMS-fähig. Ab ca. 1987 hatten die PC's die EMS-Controller z.T. auch schon eingebaut, da sie nun schon oft auf dem Motherboard auf 2 MB Speicher erweitert werden konnten. Mit EMS konnte man bis zu 512 16K-Bänke verwalten, also bis max. 8 MB. Die ersten Above-Boards brachten allerdings nur maximal 2 MB auf dem Board unter. Mir ist nicht bekannt, ob es die Möglichkeit gab, mehrere Boards simultan zu betreiben. Jedenfalls änderte sich die Situation in den Folgejahren mit dem Aufkommen von 1 MBit-Chips schnell: Nun waren 8 MB auf dem Board kein Problem mehr. Die Funktionsweise von EMSDer Programmierer kann bis zu vier 16K-Banks, hier Pages genannt, im Conventional Memory für den Datenaustausch reservieren. Der Bereich oberhalb von 1 MB heisst "Expanded Memory". Der Programmierer belegt nun eine Page, ruft eine bestimmte EMS-Funktion auf, die wiederum den Inhalt ins Expanded Memory schreibt. Der Programmierer bekommt eine Kennzahl, ein s.g. Handle zurück, die diese Page identifiziert. Nun kann er diesselbe Page im Conventional Memory wieder beschreiben. Und wieder durch die EMS-Funktion im Expanded Memory "abspeichern" lassen. Usw. Das Ganze kann er solange machen, bis 7 MB Expanded Memory voll sind. Will er die Daten wieder haben, übergibt er der entsprechenden Call-Funktion des EMS-Treibers den Handle und die Nummer der gewünschten Page (0 bis 3), in die der Abschnitt des Expanded Memories kopiert werden sollte. Das EMS-System hatte den Nachteil eines jeden Bankswitching-Systems: Es war langsam und es verlangte vom Programmierer eine Menge Speicherbuchhaltung. Spulen wir nun ein paar Jahre vor, z.B. ins Jahr 1990. Dies war das Jahr, in dem die 640K so langsam richtig knapp wurden. Inzwischen gab es nur noch wenige PC's, das meiste waren AT's und 386er-PC's. Beide beherrschten den Protected Mode und waren in der Lage, 16 MB und mehr Speicher anzusprechen. Gab es viel Motivation, EMS zu nutzen? Nein, eigentlich nicht. Dazu hätte ich PC's, die eigentlich problemlos mit 16 MB Speicher umgehen können, mit einem Memory- Expansion-Board ausstatten müssen! Irgendwie haben IBM und Microsoft mit EMS an ihrer eigenen Entwicklung vorbeigearbeitet. Der AT war schon auf dem Markt und es war klar, dass der PC gerade für Large Memory-Anwendungen nicht die Basis werden würde. Dieser wenig weitsichtigen Planung haben wir ein ziemliches Verwirrspiel in den 90er-Jahren zu verdanken. XMSDer 80286 mit seinem Protected Mode blieb bei der Festlegung des EMS-Standard also ausserhalb des Blickfelds. Der Protected Mode konnte wiederum unter DOS nicht genutzt werden, solange ein Programm DOS-Systemaufrufe (insbesondere für Datenträgeroperationen) benötigte. Aber er konnte genutzt werden, um ein Bank Switching zu simulieren, d.h. die Pages zwischen Conventional Memory und AOM auszutauschen. Dazu brauchte es nur einen cleveren Treiber, der den 80286 in den Protected-Mode schaltete, den Inhalt hinauf- oder hinunterkopierte und dann wieder in den Real-Mode zurückschaltete. Schon ein Jahr nach Verabschiederung der ersten Version des EMS-Standards legte das LIM-Konsortium für diese Art von Paging einen zweiten Standard fest: XMS 1.0. XMS war also der Standard für eine Software-Lösung des Pagings auf 286-Systemen (oder auf höheren Prozessoren). Es war EMS in vielerlei Hinsicht überlegen:
EMS- und XMS-Systeme wurden unter dem Namen "Memory Extender" (wohl zu unterscheiden von den späteren "DOS-Extendern") zusammengefasst. Solche Memory-Extender-Software wurden ab 1987 von verschiedenen Firmen wie PharLap, Quarterdeck und Quemm herausgebracht. Sie beinhaltete meist sowohl den EMS- als auch den XMS-Standard. Der Weg für Programmierer über die 640K-Grenze hinaus war also möglich, aber er war steinig:
Schwerer, als der Aufwand, wog für die meisten Software-Hersteller, dass man bei Nutzung von Memory-Extendern die zugehörige Extender-Software voraussetzen musste und damit entweder das Programm verteuerte (wenn man selbige gleich mitlieferte) oder den Kundenkreis von vornherein stark einschränkte. Dies war der Grund, warum Memory-Extender zwar für Eigenentwicklungen genutzt wurden, jedoch die Hersteller von Standardsoftware darauf verzichteten und lieber die tollsten Kunststücke und wahre Swap-Orgien auf die Festplatte vollbrachten, als Extended Memory einzusetzen. Die Situation änderte sich mit dem Erscheinen von MS-DOS 4.0 1990. Diese Version brachte u.a. ein kleines, unscheinbares Stück Software namens Himem.sys mit. Dahinter verbarg sich nichts anderes als ein vollwertiger XMS-Treiber. Ab diesem Zeitpunkt konnte jeder DOS-User XMS nutzen. Merkwürdigerweise sprangen die Software-Firmen (incl.Microsoft selbst) nicht gerade begeistert auf den neuen Zug auf. Der Doom-Vorgänger, der erste Ego-Shooter "Wolfenstein 3D", nutzte XMS. Der Packer pkzip nutzte XMS. Aber viele Programme dieser Zeit und danach für DOS, MS-Word 5.0 und 5.5, das erste Office-Paket, die Borland- und Microsoft-Compiler bis 1993, usw., sie alle ignorierten XMS. Dass der XMS -Standard sich selbst keine grossen Hoffnungen machte, den Kampf im Conventional Memory um jedes Byte zu beenden, beweist er mit seinem eigenen Design. Es zählt vielleicht zu den absurdesten¦Varianten dieses Kampfes um jedes Stückchen Freiraum unterhalb der 640K-Grenze Wie oben schon erläutert, basiert der Adressraum des 8088/86 auf 20 Bit, die aber mit Hilfe von zwei 16-Bitadressen in Programmen beschrieben werden. Diese beiden 16-Bit-Adressen werden um 4 Bits verschoben miteinander addiert. In Hex-Schreibweise (16er-System: Jede Ziffer geht von 0 bis F und repräsentiert 4 Bit): Segment: C A 8 F Offset: + C 1 1 A ------------------------ 20-Bit-Adr. D 6 A 0 A PC-Maschinenadressen notiert man als CA8F:C11A. Die letzte 20-Bit-Adresse kann man also durch Segment: F F F F Offset: + 0 0 0 F ------------------------ 20-Bit-Adr. F F F F F ,d.h. FFFF:000F bilden. Oder durch FFFE:001F. Usw. Aber was ist mit FFFF:0010? oder FFFF:FFFF? Diese Adressen liegen ja oberhalb der 1 MB-Grenze! Richtig. Beim 8088/86 machte das keinen Sinn und somit interpretierte das BIOS, das zwischen CPU und RAM vermittelt, FFFF:0010 als 0000:0010. Ab dem 80286 aber gab es ein Bit, mit dem man Adressleitung 20 (Numerierung: 0..20), die ja nun existierte, "freischalten" konnte, damit dem logischen Adressbereich FFFF:0010 bis FFFF:FFFF (das sind 64K-16) ein phyischer Speicher entsprach. Diese Umschaltbarkeit nennt man "A20-Gate". Wie knapp der Hauptspeicher anfangs der 90er war, kann man daran ersehen, welchen Aufwand man betrieb, diese kostbaren 64K im AOM zu ergattern. Der XMS-Standard legte nämlich den Austausch-Speicher, den s.g. Paging-Buffer, genau in diesen Bereich. Der Treiber Himem.sys brachte die Routinen zum Ansprechen der HMA gleich mit. Man konnte diese Routinen auch dazu benutzen, andere residente Programme, insbesondere die DOS-Routinen selbst in die HMA zu verfrachten - das schränkte natürlich wiederum die Leistungsfähigkeit eines XMS-Extenders ein. Ein weiteres Kapitel der Memory-Extender wurde mit Erscheinen des 80386-Prozessors 1986 aufgelegt, aber darauf komme ich dann im 80386-Kapitel zurück. |
Speicherkarte eines PC's

80386-PC'sDie Zeit zwischen 1989 und 1991 war pc-seitig eine seltsame Zeit. Die Zeit der 80386 hatte 1986 begonnen, aber erst 1989 begannen sie in den Bereich unter 10.000 DM einzudringen und wurden langsam in nennenswerten Stückzahlen verkauft. Der 80386 brachte einen gegenüber dem 80286 stark erweiterten Protected Mode mit, auf seinem 32 Bit breiten Adress- und Datenbusse 4 GB Adressraum anbietend, das auch in linearer Adressierung und - im richigen Betriebmodus - mit Adress Protection. Vorausgesetzt, Programme und Betriebssystem unterstützten dies. Und noch mehr: Es gab auch die Möglichkeit, parallel zum Protected Mode Prozesse im s.g. Virtual-8086-Mode anzustossen. Virtual deshalb, weil in DOS natürlich nicht mehrere Prozesse nebeneinander exisitieren konnten. Aber es war möglich, auf jedem der Virtual-8086-Prozesse ein separates DOS zu fahren. Linux oder Windows NT gab es noch nicht, nicht einmal Windows 3.0 war schon auf dem Markt oder nennenswert verbreitet. DOS kannte keinen Protected und schon gar keinen Virtual-8086-Mode. Es gab nicht wenig Hersteller und Händler, die 1988/89 einen damals noch sehr teuren 386-Rechner anboten, mit 1 bis 2 MB RAM und unter DOS. Und die meisten Kunden werden ihn so stolz benutzt haben, ohne jemals auf die Idee gekommen zu sein, dass sie nur 30% ihres Rechners überhaupt nutzten - sowohl, was die Prozessorpower,als auch, was den Hauptspeicher anbelangte. Mir selbst ist ein Fall bekannt, in dem eine Firma 1987 einen 386er anschaffte (mit wieviel Speicher, das weiss ich nicht, aber dem mir genannten Preis nach zu urteilen, waren wahrscheinlich 1 MB oder mehr drin.) Sie übertrugen ein Grossrechnerprogramm auf Fortran unter DOS. Und erweiterten es immer mehr und kämpften mit der 640K-Grenze, wie man nur kämpfen konnte (13.000 Zeilen Programmcode). Doch selbst 1995 kamen sie nicht auf die Idee, dass es einen Ausweg aus dem DOS-Gefängnis geben könnte. Es gab ihn. Und nicht nur einen. Und nicht erst 1995. Der erste Ausweg hiess XMS. Das beherrschte der 80386 noch viel besser als der 80286. Im 32-Bit-Protected Mode war er ab LIM-Standard 3.0 in der Lage, nicht nur 16 MB, sondern theoretisch 4 GB zu adressieren. Theoretisch. Kein mir bekanntes Programm ist in der Lage, unter XMS mehr als 64 MB zu adressieren. Das 64 MB-Limit rührt daher, daß in dem Moment, in dem das System selbst den zur Verfügung stehenden Speicher über das BIOS ermittelt, es diesen von DOS über eine 16-Bit-Zahl mitgeteilt bekommt - in Kilobyte zum Glück... Eine weitere Möglichkeit mutet mir heute noch etwas seltsam an: Die damaligen kommerziellen Memory-Extender für 386-Prozessoren beherrschten neben XMS auch EMS. Vielleicht konnten das auch Versionen für 286-Prozessoren, das weiss ich nicht. Wohlgemerkt: EMS via Software, nicht via Expansion Board. Einfach dadurch, dass EMS-Routinen angeboten wurden, die intern alles in XMS übersetzten (was ja nicht schwer war). "XMS emuliert EMS" hiess das dann. Wozu sollte das gut sein? Nun, obwohl XMS schon 1986 das Licht der Welt erblickte, wurde es bis 1990 so gut wie ignoriert. Ich vermute fast, dass die damalige Memory-Extender-Software auch auf 286er-Systemen EMS anbot - um der lieben Kompatibilität mit den wenigen alten PC- Oldtimern mit Expansion Board willen. Und das hat sich dann mal wieder verselbstständigt: Die Software-Hersteller setzten auf EMS und die Memory-Extender-Hersteller sahen keinen Grund, auf XMS umzusteigen. Borland jedenfalls nutzte meines Wissens nach 1991 zum ersten Mal einen Mem-Extender und das war EMS. In Turbo Pascal 6.0 wurde der Editor damit beglückt, damit das Turbo Vision-Fenster-System überhaupt einen Sinn machte. Für den Programmierer blieb ansonsten alles beim alten:
Erst mit Turbo-C++ 3.0, bzw. Turbo-Pascal 7.0 hielt XMS in die IDE Einzug - 1993. Die ganze IDE arbeitete mit XMS, so dass, wenn auch nur Real-Mode-Programme entwickelt werden konnte, diese wenigstens den gesamten (500 bis 600K) grossen Speicher nutzen konnten. Als 1991 DOS 5.0 herauskam, hatte es ein besonderes Schmankerl dabei: EMM386. Ich vermute, dass kaum jemand damals begriff und heute weiss, was es mit diesem obskuren EMM auf sich hatte. Nun, es war ein lizenzierter EMS-Emulator. (Siehe oben). AusschlieÜlich für 386er. Ohne ihn wären manche Programme ohne eigens angkauften Memory-Extender gar nicht oder nur innerhalb von 640K gelaufen - z.B. Turbo Pascal 6.0. Und das alles wegen einer Handvoll exotischer IBM PC's 1984... DOS-Extender, DPMI und VCPIEs gab noch einen dritten Weg, 1987ff. an den Speicher eines 386er zu gelangen: Die Nutzung eines DOS-Extenders. DOS-Extender realisierten auf einem 386er das, was auf einem 286er unter DOS meines Wissens nach nicht möglich gewesen war: Die dauerhafte Nutzung des Protected Mode. Gegenüber Memory Extendern hatten sie den grossen Vorteil, die inneren Speicherstrukturen nicht mehr in eine Paging-Verwaltung umsetzen zu müssen. Abgesehen vom Zuwachs an Rechengeschwindigkeit, der aus dem Wegfallen des Pagings und der Nutzung eines echten 16-Bit oder 32-Bit-Betriebsmodus resultierte. Wie benutzte man DOS-Extender? Man kaufte sich eine solche Software, band sie in seinen Linker ein, dann schrieb man sein Programm, das die 1 MB-Grenze geflissentlich ignorierte und anschliessend konnte man dem Linker die Anweisung geben, das Programm für den Protected Mode umzusetzen. Um das Programm auszuführen, brauchte man bei den meisten Extender eine kleine Runtime-Datei, die man zusammen mit seinen Programmen frei verteilen durfte. Grössten Bekanntheitsgrad dürfte der DOS-Extender DOS4GW bekommen haben- ihn wird der ein oder andere von Spielen her noch kennen. Warum gab es EMS und XMS, wenn es auch so einfach ging? Nun, zunächst sind EMS und XMS Kinder der Vor-386--ra. Zweitens aber war die Realisation eines DOS-Extenders eine technisch sehr aufwändige Sache, so dass, solange es DOS gab, die bekannten DOS-Extender nie so frei zugänglich waren, sondern immer eine Stange Geld kosteten. Während ab DOS 4.0 der XMS-Treiber Himem.sys eine kostenlose Dreingabe von DOS wurde. Mit DOS-Extendern zu entwickeln, blieb den Profi-Entwicklungssystemen vorbehalten. Es gab allerdings auch Freeware-DOS-Extender, z.B. für die Borlandprodukte den Swallow-Extender Download hier), die auch ziemlich problemlos einsetzbar waren. Der Nachteil des Swallow ist, dass er nicht im Grafik-Modus funktioniert - ein Handicap für Spieleprogrammierer. Auch sonst ist DOS-Extender nicht gleich DOS-Extender. Es gibt 16-Bit- (ab 80286) und 32-Bit-Protected-Mode-(ab 386)-Extender. Es gibt Extender, die den Grafikmodus ermöglichen und welche, bei denen es nicht geht. Fast alle Extender haben enorme Probleme, den Betrieb eines Debuggers zu ermöglichen. Z.B. funktioniert der Debugger im Protected Mode in BP7.0 nicht. Bei den Watcom-Compilern funktionierte er, aber nur über ein aufwändiges Threading (unter DOS wohlgemerkt!). Wie funktioniert ein DOS-Extender? Das weiss ich auch nicht so genau. Eine gewisse Rolle spielt dabei wohl der Virtual-8086-Mode des 386er. Das Problem sind ja unter DOS die DOS-Aufrufe und insbesondere die Rückkehr zum Betriebssystem. Solange ein Programm ganz ohne Dateizugriff arbeitet, den Bildschirmspeicher direkt beschreibt und der PC nach Beendigung des Programms neu gebootet wird, sind Protected Mode-Programme auch auf dem 80286 kein Problem. Sollen aber Datei-, Bildschirm- und Druckerzugriff von DOS genutzt werden, muss DOS im Real Mode aufgerufen werden. Das heisst, jeder Dateizugriff erfordert ein Hin- und Herschalten. Diese Umschaltung ist naturgemäss nicht besonders schnell. Sie ist aber insbesondere enorm heikel, da die Inhalte sämtlicher adressbezogener Register im jeweils anderen Mode bedeutungslos werden. So einen DOS-Extender hat wohl nie jemand geschrieben. Die DOS-Extender für den 386er haben die Umschaltung nicht nötig. Sie lassen das Progamm im Protected Mode laufen und parallel dazu einen Virtual-8086-Prozess und darin DOS. Jeder DOS-Aufruf wendet sich an diesen parallel laufenden Prozess. Und fertig ist die Laube. Da nun aber DOS im Real Mode und die Programme im Protected Mode laufen, sind die Programme praktisch ohne Oberhoheit, besonders, was die Speicherverwaltung angeht. Zwei Protected Mode-Programme gleichzeitig können sich, müssen sich fast irgendwann gegenseitig in die Speicherbereiche schreiben. Um das zu verhindern, entwarfen Lotus und Pharlap eine Art Betriebssystem-Aufsatz für den Protected Mode, den VCPI-Standard. DOS-Extender, die dem VCPI-Standard genügten, nannte man daher auch VCPI-Extender. Programme mit VCPI-Extender brauchen also zwei Assistenten: Das VCPI-System, das den Speicher verwaltet und den eigentlichen DOS-Extender. Programme,die VCPI nutzten, waren nur mässig verbreitet. Mir sind hauptsächlich Programme aus der Statistik und Numerik bekannt. Als Microsoft 1990 sein Windows 3.0 herausbrachte, war ein DOS-Extender das Mittel der Wahl, die gestiegenen Ansprüche an Ressourcen und Speicher mit der weiterhin existierenden DOS-Gebundenheit zu koppeln. Und es wäre naheliegend gewesen, dafür einen VCPI-Extender zu verwenden. Vermutlich wegen der Lizenzkosten, vielleicht auch aus marktpolitischen Gründen und vielleicht auch, weil Microsoft nun mal Microsoft ist, taten sie das nicht, sondern entwickelten ihren eigenen Standard. DPMI, das DOS Protected Mode Interface. Immerhin enthielt Windows auch einen VCPI-Treiber, der VCPI in DPMI sozusagen übersetzte, so dass auch VCPI-Programme unter Windows liefen. (Siehe DPMI-Dokumentation von Tenberry) Damit hatte man 1990 unter einem Windows-Entwicklungssystem zumindest volle Protected-Mode-Eigenschaften - endlich: Bis zu 64 MB Speicher, wenngleich dieser immer noch in 64K-Blöcke segmentiert war. (Es war bis 1994 selten, dass ein PC mehr als 16 MB Speicher hatte.) Für Programmierer, die keine GUI's brauchten, war Windows aber zunächst keine ideale Umgebung. Ein einziger Pointerfehler und schon war das ganze Windows abgeschossen. Dann hiess es: DOS hochfahren, Windows hochfahren, IDE hochfahren, Programm laden. Für "Nicht-GUI's" war es das Beste, unter Windows 3.x im DOS-Fenster zu arbeiten. Dann brauchte man bei einem Programmierfehler, sei es unter Turbo Pascal oder Turbo C++, nur ein neues DOS-Fenster aufzumachen und die IDE neu hochfahren. Die Versionen der "Turbo"-Produkte von Borland, die seit 1992 auf den Markt kamen, machten von DPMI Gebrauch: Die IDE lief selbst komplett mit DPMI, was es ermöglichte, innerhalb der IDE Binaries zu entwickeln und zu debuggen, die den 640K-Bereich bis zum Rand füllten, mithin ein Entwicklungsvolumen im Megabytebereich aufwiesen. Seit 1992 unterschied Borland auch zwischen Standard- und Professionalprodukt. Das Professionalprodukt hob sich vom Standardprodukt im Wesentlichen dadurch ab, dass es dem Nutzer erlaubte, selbst 32-Bit-DPMI- Programme zu schreiben. Was bedeutet eigentlich 16-Bit und 32-Bit? Das hat mit der Adressierung im Protected Mode zu tun, der s.g. virtuellen Adressierung. Vorbei die Zeiten von physikalischen Adressen aus 16, 24 oder 32 Bit. Im Protected Mode wird die Idee der Segmente weiter fortgeführt, indem eine virtuelle Adresse sich zusammensetzt aus einem s.g. 16-Bit-Segmentselektor und einem Offset-Selektor. Der Segmentselektor gibt eine Adresse in einer Tabelle im Hauptspeicher an und erst dort steht, wo sich das Segment eigentlich befindet. Beim 80286 ist der Offset-Selektor 16 Bit breit, ab dem 386 32 Bit, d.h. hier können die Segmente bis zu 4 GB umfassen. Was erhellt, warum es möglich ist, mit dem 80386 in flacher Adressierung zu arbeiten. Um Missverständnisse zu vermeiden: Wenn mit 32-Bit-Segmenten gearbeitet wird, macht die Arbeit mit Segmenten eigentlich gar keinen Sinn mehr, da der Adressraum nur eines 32-Bit-Segments in einen 32-Bit-Adressraum reinpasst... Entsprechend ist in diesem Fall in der LDT, der Local Descriptor Table, wo die physischen Basisadressen der Segmente stehen, nur ein Eintrag: Ein Segment und dieses zeigt auf Basisadresse null. Theoretisch jedoch ist der logische Adressraum 48 Bit breit, weil theoretisch mehr 32-Bit-Einträge als nur einer in der LDT denkbar wären. So kommt die Vorstellung von "48 Bit" zustande: Ein 16-Bit-Selektor des Tabelleneintrags (der allerdings separat im DS-Register gespeichert ist) und die 32-Bit breite Offset-Adresse. Entsprechend unterscheiden sich die DOS-Extender: Die einen sind für den 80286, die anderen für den 80386 ausgelegt, die einen segmentieren ihren Speicher in 64K-Häppchen, die anderen benutzen ein grosses 32-Bit-Segment. BP 7.0 war insofern ein lustiger Zwitter, weil der Compiler für eine Adresse vorsichtshalber 48 Bit reserviert, obwohl der beigefügte DOS-Extender nur ein 16-Bit-Extender ist, also lediglich mit 16-Bit-Segmenten umgehen kann. Findige Programmierer haben später flux einen 48-Bit-Extender progammiert, so dass sie es schafften, auch mit dem BP 7 echte 48-Bit- (im landsläufigen Sinn "32-Bit-Software") zu schreiben. Sehr theoretisch waren damit 256 TB adressierbar ;-)). Wer sich allerdings nun vorstellt, mit oder ohne DOS-Bit-Extender- so problemlos in einem 16 MB-Speicher herumprogrammieren zu können, wie unter Linux oder MacOS, der hat sich getäuscht. Neben einigen Einschränkungen, auf die ich gleich noch komme, lief der Debugger für Protected Mode-Programme nicht. Weder der interne noch der externe. |
|
Diese Limits - man könnte sie im Zeitalter an der Schwelle zu
den
64-Bit-Systemen getrost als Bugs bezeichnen - sind wohl kaum einer
Kompatibilitätsüberlegung geschuldet, sondern eher etwas
willkürlichen
Ausflügen der Compilerhersteller in die 16-Bit-Adressierung. Dem
Anwendungsprogrammierer
werden sie in der Regel nicht auffallen, es sei denn, er arbeitet
mit entsprechend hohen Speicherlasten. Dann kann er damit gehörig
auf
die Nase fallen.
Die 64 MB-Grenze von DOS/Win 3.x kennt 32-Bit-Windows nicht. Hier wird's erst unter Win9x/ME bei 512 MB langsam eng. Die Speicherverwaltungs- routine von Win9x, die z.B. beim Beenden eines Tasks den Speicher aufräumt, operiert nur bis zur 512 MB-Grenze. Als Programmierer kann man sich auch jenseits davon Speicher reservieren, aber Sicherheit ist dann nicht mehr garantiert, daß man nicht Code oder Daten eines anderen Tasks überschreibt. Das dürfte allerdings kein grundsätzliches Handicap sein. Sicher gibt es Anbieter für bessere Speichermanager, die das Problem bis zur 4 GB-Grenze beheben. Ausserdem wird die alte Windowslinie bis ME wohl ausgestorben sein, wenn Speicher oberhalb 512 MB zum Standard werden. Unter NT und 2000, wie auch unter Linux ist der 4 GB-Raum ohne Limit nutzbar. (Testen konnte ich das allerdings bisher noch nicht!) Überblick: Die Hauptspeicherverwaltung der Windows-VersionenWindows 1.x
Windows 2.x2 Betriebsmodi: Real ModeWie Windows 1.x286 Mode
Windows 3.03 Betriebsmodi: Real ModeWie Windows 1.x286 ModeWie Windows 2.x386 Enhanced Mode
Windows 3.1x2 Betriebsmodi: 286 ModeWie Windows 2.x386 Enhanced ModeWie Windows 3.0Win32sBetriebssystemaufsatz f. Win3.1x. Besteht aus "thunking"-Interface und eine kleine API im 32-Bit-Flat Model. Programme, die im Flat-Model arbeiten, greifen über die Win32s-API auf die segmented Win3.1-API zu. Windows95/98/ME
Windows NT/2000/XP/2003
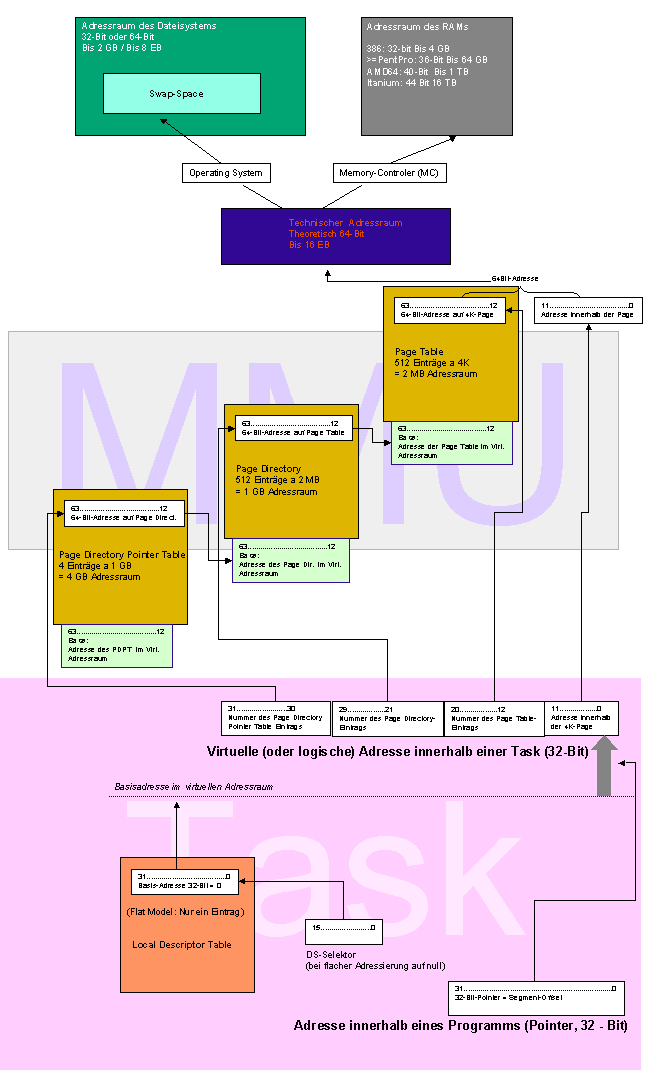
Hauptspeichermanagement mit PagingEinleitung zum PagingWas ist denn das schon wieder? Schon wieder Speicher in Bröckchen? Pages waren doch schon bei EMS und XMS da. Ach ja, und überhaupt war der Speicher die ganze Zeit in 64K-Blöcke aufgeteilt. Waren wir das im 32-Bit-Mode nicht endlich los? Nein. Es wird noch schlimmer. Es geht hier nicht um 64K-Happen, sondern um 4K-Häppchen... Das Paging-System wurde mit dem 80386 eingeführt. Es hat nichts mit dem Deskriptoren-Modell des Protected-Mode zu tun, sondern löste dieses quasi ab. Aus Kompatibilitätsgründen kann man beide simultan betreiben (damit 16-Bit-Software wie das gute alte MS Word6, auf dem gerade diese Zeilen entstehen, auch noch auf einem 80386 laufen), aber beim 80386 hat das Deskriptorenmodell keine Taskverwaltungsfunktion mehr. Das Prinzip des Paging-Systems des 80386 wurde bei allen Prozessoren bis heute beibehalten. Es ist auch so in etwa in der AMD64- und IA64-Architektur enthalten. Das, was gerade so auf uns zukommt, nämlich die 4 GB-Schwelle, ihre Limits und Nicht-Limits, die Erweiterungen (PSE, PAE) und dass 64 Bit kein 64 Bit ist, kann man nur auf Basis des Pagings verstehen. Die Hauptspeicherverwaltung eines modernen PC's muss auf zwei Ebenen stattfinden. Zum einen gibt es die Möglichkeit, Hauptspeicher ins Filesystem auszulagern, den s.g. Swap-Space. Manchmal spricht man hier auch von "virtuellem" Hauptspeicher. Das "Virtuell" möchte ich hier aber vermeiden, weil es zur Verwirrung mit der später anzusprechenden virtuellen Adresse kommen könnte. Beide haben nichts miteinander zu tun. Hauptspeicher besteht also vor der ersten Ebene aus Swap-Space und RAM. Beides muss zu einem gemeinsamen Adressraum zusammengeführt werden. Das ist die eine Aufgabe. Die zweite ist es, diesen "technischen Speicher" dann an die einzelnen Tasks zu verteilen. Und zwar so, dass die Tasks virtuelle Adressen sehen und nur der Speichermanager der CPU, die s.g. MMU, diese in eine Adresse des gemeinsamen Adressraums übersetzen kann, also weiss, wohin was gehört. Beide Aufgaben gleichzeitig werden dadurch erschlagen, dass die MMU den Speicher in Pages aufteilt. Sowohl die virtuellen Speicherräume als auch den technischen Adressraum. Ausser in ein paar Ausnahmefällen, auf die ich hier nicht eingehe, sind diese Pages bei x86-Prozessoren 4K gross. Fordert ein Task Speicher an, so bekommt er immer mindestens 4K. Daher hat man die Pages nicht grösser gemacht: Man will den "Verschnitt", die Grösse des eigentlich gar nicht benutzten Speichers, nicht zu gross werden lassen. Die Pages werden von der MMU in einer Tabelle verwaltet, der s.g. Page Table. Ein Eintrag in dieser Tabelle ist 32-Bit breit. Die MMU benötigt aber nur 20 Bit, da alle Pages im technischen, gemeinsamen, 32-Bit grossen Adressraum logischerweise bei Vielfachen von 4K beginnen. Die Adresse innerhalb einer Task besteht also aus zwei Teilen: Die unteren 12 Bit sind sozusagen der echte Page-Offset im technischen Adressraum. Die oberen Bits geben an, die um welche Page in der Page Table es sich handelt. Und erst dort stehen die fehlenden 20 Bit der eigentlichen Adresse. Daher haben die Pointer-Adressen in modernen 32-Bit-Systemen meist viele führende Nullen: Da die Tasks in der Regel nur ein paar Megabyte ihres 4 GB-Adressraums brauchen, werden nur die ersten der ca. 1 Mio. möglichen Pages angesprochen. Und da jeder Task seine eigene Page Table hat, (wir erinnern uns: Wie beim 16-Bit-Protected Mode jeder Task seine eigene Local Descriptor Table hatte...), stehen die Einträge alle fein säuberlich hintereinander. Page Table DirectoriesEin technisches Detail ist, dass 4 GB "ein Mega" = 1,048 Mio. Einträge in der Page Table benötigen. Ein Eintrag benötigt selbst 4 Byte, so dass die Page Table in diesem Fall 4 MB Speicher benötigt. Das heisst, sie benötigt selbst 1024 Pages. Wo stehen aber diese Pages im "technischen Adressraum"? Dazu muss es wiederum eine besondere Page Table geben und die hiesst "Page Table Directory". Also: Jede Task bekommt bis 1024 Page Tables und ein Page Table Directory zugewiesen, über das die MMU ermitteln kann, welche Adresse des virtuellen Adressraums jeweils dem "technischen" Adressraum entspricht. Entsprechend werden die oberen 20 Bit für den Page Table-Eintrag in zweimal 10 Bits aufgespalten: Die obersten 10 Bit verweisen auf den zuständigen Eintrag im Page Table Directoy, die mittleren 10 Bit auf den Eintrag in der jeweiligen Page Table und die unteren 12 Bit stellen eben den Adress-Offset dar. 4 GB or not 4 GBDamit kommen wir langsam zu der spannenden Frage, wo denn die Speichergrenzen bei 32-Bit-Systemen liegen. Wir sehen auf alle Fälle, dass es mehrere Adressräume gibt und jeder von ihnen ein begrenzender Faktor darstellt:
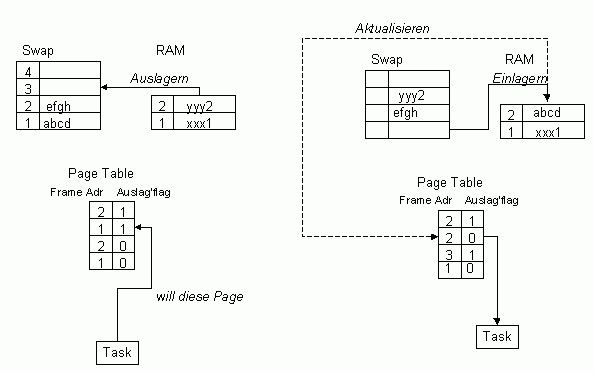
Die Grösse des technischen Adressraums bestimmt, wieviel Speicher alle Tasks zusammen belegen dürfen. Die Grösse des virtuellen Adressraums, wieviel Speicher eine Task belegen kann. Die Breite eines Pointers besagt nur, wie breit Adressangaben innerhalb der Programme sein müssen, ohne etwas darüber auszusagen, wieviel Bits davon wirklich interpretiert werden. Wir hatten das beim 808x auch schon: Die Heap-Pointer waren 32 Bit, interpretiert wurden nur 20 Bit. Task-LimitsSomit müsste ein Task 4 GB belegen können. Oder zumindest annähernd 4 GB, da ja der technische Adressraum auch auf 4 GB beschränkt ist und das Betriebssystem auch noch Speicher braucht. Wenn man das Experiment macht, stellt man enttäuscht fest, dass nach 2 GB bereits Schluss ist. Warum? Nun, wir hatten uns weiter vorne mit der 640K-Grenze beschäftigt. In Diskussionsforen pflegt man heute den Kopf zu schütteln vor soviel Beschränktheit, damals dieses 640K-Limit so fest verankert zu haben. Kann man eigentlich nur mit der technischen Rückständigkeit der damaligen Zeit erklären, oder? Nun, das 2 GB-Limit ist nicht viel anderes als das 640K-Limit des technischen Adressraums. Oberhalb der 2 GB-Grenze blendet die MMU die Adressen des technischen Adressraums sozusagen 1:1 in den virtuellen Adressraum ein. Warum? Aus genau den gleichen Gründen, aus denen man vor 20 Jahren die UMA freigehalten hat: Damit Peripherie-Hardware feste Adressen zugewiesen werden können. So sitzt hier der Adressraum des PCI-Busses, des AGP-Busses, der Schnittstellen usw. Darüberhinaus sitzen hier aber auch die Routinen des Betriebssystem-Kernels. Man hat diese Adressen nicht dem Paging unterworfen, weil sonst die Zugriffsgeschwindigkeit auf die entsprechenden Speicherbereiche durch den MMU-Übersetzungsvorgang drastisch zurückgegangen wäre. Im "Normalfall" ist man also auf 2 GB pro Task beschränkt. Die Betriebssystem-Kernel von Linux und Windows können allerdings auch in einem s.g. 3/1-Modus arbeiten: Task=3 GB, Kernel=1 GB Adressraum. Dazu muss man den Linux-Kernel neu kompilieren. Bei Windows klappt dieser 3/1-Betrieb nur mit speziellen Server-Versionen von WindowsNT/2000 (Enterprise, bzw. Enterprise,Datacenter) und mit Windows2003. Hier müssen Parameter in der boot.ini angegeben werden. Theoretisch 8 GBNach der bisherigen Darstellung ist der technische Adressraum aus RAM und Swap zusammen 4 GB gross. Warum eigentlich nicht 8 GB? Schliesslich müssen die 20-Bit-Adressen in den Page Table-Einträgen, die s.g. Frame-Adressen, da sie auf verschiedene physische Speicher verweisen, nichts miteinander zu tun haben. Und schliesslich dient ein Attributflag dazu, festzustellen, ob eine Page ausgelagert ist oder nicht, also als Unterscheidung zwischen den beiden Adressräumen. Mithin müsste der technische Adressraum 33-Bit-Adressen besitzen. Die Frage ist lediglich, ob es nicht für Betriebssysteme ratsam ist, für den Swap Space zum RAM disjunkte Adressen zu verwenden. Ein Beispiel mit lediglich zwei RAM- und vier Swap-Pages, wo dies nicht so ist, ist in der folgenden Abbildung dargestellt.
Leider habe ich kein System, mit dem ich das mal ausprobieren könnte und habe darüber auch bisher nichts gefunden, so dass ich nicht sagen kann, ob ein PentiumPro(+) im Standardbetrieb (also ohne PAE, siehe weiter unten) für alle Tasks gemeinsam 4 GB oder 8 GB technischen Adressraum bereithält. Jenseits der 32 BitEs liegt nahe, an der Schwelle zur 64-Bit-Zeit zu fragen, ob sich der Übergang ähnlich schwierig gestalten wird, wie der Übergang von der 16- in die 32-Bit-Welt. Wird es eine 4GB-Segmentierung geben? Und ein 40 GB-Limit, so wie es ein 640K-Limit gab? Nun, das Zeitalter jenseits 4 GB ist längst schon eröffnet. Zu einer Zeit, in der selbst Power-Anwender kaum an die 4 GB-Grenze stossen werden. Lediglich in dem Bereich, der 1980 "Grossrechnerbereich" geheissen hätte, also im Bereich z.B. von Datenbanken grosser Unternehmen und den entsprechenden Servern oder im Bereich von professioneller Animationsproduktion und Videoverarbeitung dürfte die 4 GB-Grenze schon ein Thema sein. Ca. 1994 brachte Intel den ersten Prozessor der Linie P6 heraus, den Pentium Pro. Prozessoren dieser und späterer Linien haben einen 36-Bit breiten physikalischen Adressbus. Obwohl der Befehlssatz weiterhin mit 32-Bit-Adressen arbeitet. Wir haben also quasi die umgekehrte Situation wie früher: Nicht breitere logische Adressen als physische Adressbreite (32 Bit und 20 Bit beim 8088/86), sondern umgekehrt. Physisch kann ein PentiumX, X=Pro,II,III,4 also 64 GB adressieren. Aber natürlich gibt es heute ähnliche Schwierigkeiten, an den Speicher heranzukommen, wie vor 15 Jahren an den 16MB-Speicher eines 80286. Aus genau dem gleichen Grund: Kompatibilität, der eine Veränderung des Befehlssatzes auf 64 Bit untergeordnet wird. Hätte Intel den Befehlssatz beim PentiumX geändert, würde kein Binary mehr auf einem Pentium UND einem PentiumX laufen. Sondern nur entweder oder. Das sollte vermieden und der 386-Befehlssatz beibehalten werden. Hurra, wir dürfen wieder basteln! PSE36Die erste Lösung, die sich Intel hat einfallen lassen, um die 36 Adressbeinchen einer modernen Pentium-CPU auch einem Zweck zuzuführen, nennt sich PSE36. Hier wird kurzerhand festgelegt, dass jeder Page-Table-Eintrag nicht eine 4K-Page, sondern eine 4M-Page adressiert. Damit kann ein Page-Table-Eintrag mit seinen 20 Bit natürlich nicht nur 4 GB adressieren, sondern 4 TB. Die virtuelle Adresse wird dann in 10 plus 22 Bits aufgeteilt, für die "Ausleuchtung" eines 4 GB-Adressraums sind nur noch 2^10 Pages notwendig, die natürlich alle in eine 4M-Page gehen - ein Page Directory ist nicht mehr notwendig. Der Nachteil des Verfahrens ist auch klar: Enorm viel ungenutzter Speicher. Jede Task, auch wenn sie nur 10K Speicher anfordert, kriegt 4 MB zugesprochen. Sind 50 Tasks am Laufen, (für ein Multitasking-Betriebssystem mit seinen Diensten völlig normal) sind 200 MB Hauptspeicher gleich mal so weg. OK, auf der anderen Seite: Man wird PSE36 nur benutzen, wenn man mehr als 2 GB Hauptspeicher hat und dann sind 200 MB auch nicht die Welt... Unter Windows ist PSE36 nur mit der Enteprise-Edition von NT verfügbar. PAEPAE ist die wesentlich elegantere Lösung: Die Page Table-Breite wird von 32 Bit auf 64 Bit erweitert. Auf diese Art und Weise können volle 16 EB technischer Adressraum verwaltet werden. Schwierigkeit: Die Table braucht doppelt soviel Platz. Und damit haben nur noch halb soviele Pages in einer 4K-Page Platz. Auf der anderen Seite braucht man dann aber auch nur noch 9 statt 10 Bit der virtuellen Adresse, um einen Page Table-Eintrag anzusprechen. Es bleiben also 2 Bits am "oberen Ende" der virtuellen Adresse übrig, die man dazu verwenden kann, ein drittes Page Table-Level einzuführen. So dass man nun bis zu 4 Directories und bis zu 4 mal 512 Page Tables pro Task hat. LINUX kann mit der PAE-Option kompiliert werden. Bei Windows sind die PAE-tauglichen Versionen die Enterprise- und DataCenter-Versionen von Win2000, sowie Win2003 Server und WindowsXP, SP2. Paging in der IA32-Architektur mit PAE:
AWEAWE heisst "Adress Windows Extension" und ist ein Feature, um einzelnen Tasks unter IA32 die Nutzung von mehr als 3 GB Speicher zu erlauben. Mit AWE sind wir da, wo wir vor 20 Jahren schon mal waren: Beim XMS des Jahres 2000. Damit kann ein Programmierer bis zu 64 GB (in den bisherigen Releases nur bis 32 GB) ansteuern, die Speicherverwaltung mit eingeblendeten Fenstern usw. muss er sich allerdings selbst schreiben. Von 36 auf 64 BitIm s.g. Workstation-Markt (der Name wurde mit dem Aufkommen der SUN-Desktop-Computer Mitte der 80er geprägt und bedeutete: Maschine, die preislich und leistungsmässig eindeutig oberhalb der Alltags-PCs liegt, hauptsächlich im Bereich professioneller Grafik, Filmtechnik, Numerik, CAD usw. angewendet wird, aber ein Desktopcomputer ist, der weithingehend nur von einer Person simultan genutzt wird) gab es schon seit Mitte der 90er-Jahre 64-Bit-Prozessoren. Hauptsächlich aus Gründen der Rechengeschwindigkeit und nicht so sehr aus Gründen der 4GB-Grenze. Die x86-ArchitekturIn 2001 und 2003 kamen zwei neue Prozessorenfamilien auf den Markt, deren Befehlssätze nicht nur Erweiterungen der Befehlssätze des 80386 sind, sondern völlig eigenständig und inkompatibel zum Befehlssatz: Der Itanium von Intel und der Opteron von AMD. Es ist klar, dass mittelfristig einer von beiden der Nachfolger der 386-Familie sein wird. Kurz ein Rückblick: Wenn nun etwas abgelöst wird, was wird eigentlich abgelöst? Wir hatten bisher folgende Architekturen und damit Befehlssätze: 8086 64K-segmentierte Adressierung, 1 MB-Adressraum. 80286/Protected 64K-segmentierte Adressierung, 16 MB-Adressraum. 80386/Protected Flache Adressierung, 4 GB-Adressraum. Alle Prozessoren seit dem 80386 haben keine neuen Befehlssätze und damit keine neuen Betriebsmodi der Prozessoren mehr gebracht, sondern lediglich Erweiterungen des Befehlssatzes: MMX (Pentium/Pentium II), SSE (Pentium III) und SSE2 (Pentium 4), bzw. 3DNow (Athlon). Zu jedem der drei x86-Architekturen, die es gegeben hat, gehören entsprechende Betriebssystem-Generationen: 8086: DOS 80286/Protecetd: OS/2 und Windows 3.x 80386/Protected: Linux und Windows NT Wenn man sich das mal genau anschaut und sich vergegenwärtigt, dass Windows XP das erste Windows-Betriebssystem "für alle" ist, dem der NT-Kernel zugrundeliegt, dann heisst das, dass eben gerade erst in 2002/2003 die breite Masse anfängt, 32-Bit-Prozessoren als solche zu nutzen. Das muss man sich auf der Zunge zergehen lassen! Die Itanium-ArchitekturEtwa 1997 startete die Firma Intel ihr 64-Bit-Prozessorenprojekt, zusammen mit der Firma Hewlett-Packard. Zuerst war man sehr gespannt auf den Nachfolger der Pentiumbaureihe und nahm die Hinweise, dass es sich bei dem Prozessor in erster Linie um einen Workstation-Prozessor handeln solle, nicht besonders ernst. Als sich die Entwicklungsarbeiten jedoch jahrelang hinzogen, begriffen die Aussenstehenden, dass Intel tatsächlich wohl kein grosses Interesse haben würde, den Massenmarkt zu beliefern. So stellt sich die Situation auch heute, einige Jahre nach Auslieferung der ersten Itaniumserien dar. Es wird wohl noch bis zu 5 Jahre dauern, bis die Itaniums - wenn überhaupt jemals - in die PCs der oberen bis mittleren Kategorie diffundiert sind. Es lässt sich noch überhaupt nicht sagen, ob der Itanium einmal eine ähnliche Verbreitung finden wird, wie die 386-Prozessoren. Der Itanium ist ein reiner 64-Bit-Prozessor, dessen Befehlssatz nichts mehr mit dem 386er-Befehlssatz zu tun hat und zu diesem völlig inkompatibel ist. Um dennoch 32-Bit-Programme (386er-Protected-Mode) ausführen zu können, hat er eine Emulation eingebaut, die diesen Mode in seine eigentlichen Befehle übersetzt. Vorerst (Anfang 2004) ist er dabei ziemlich langsam und erreicht dabei nicht annähernd die Leistung der aktuellen 32-Bit-Prozessoren. 16-Bit-Programme (Real- und 286-Protected) kann er gar nicht mehr ausführen. Was heisst, dass man eine Itaniummaschine nicht unter DOS booten kann - jedoch unter 32-Bit-Linux. Die AMD64-ArchitekturDiese unterscheidet sich grundlegend vom Itanium. Auch hier ist noch überhaupt nicht zu sagen, welche Verbreitung diese Architektur einmal haben wird. Wenn man die Geschichte betrachtet, hat diese Architektur die besseren Karten als die Itanium-Architektur, das hat das Experiment Intels mit dem 80186 und iAPX-432 gezeigt: Kompatibilität ist alles. Und Kompatibität des Itanium ist dürftig. Auf der anderen Seite dürfte es schwer sein, die Marktmacht von Intel zu brechen. Hier wird die Haltung von Microsoft sowie der weitere Erfolg von Linux eine grosse Rolle spielen. Die AMD64-Architektur ist ähnlich wie die 80386-Architektur aufgebaut: Der Prozessor beherrscht alle Abwärtsmodi und dann noch seinen eigenen "Protected Mode". Zunächst unterscheidet man bei AMD64
Man kann ein Betriebssystem nur in einem der beiden Modes starten. Startet es im Legacy-Mode, verhält sich der Prozessor ganz und gar wie ein 32-Bit-Athlon, d.h. 386er. Das heisst, ein AMD64 kann auch mit DOS oder Win3.x gebootet werden, wenn einem danach ist. Im 64-Bit-Mode muss das Betriebssystem ein 64-Bit-Betriebssystem sein, da es mit 64-Bit-Adressen und -Registern umgehen können muss. Es ist aber durchaus möglich, innerhalb des 64-Bit-Systems 32- oder 16-Bit-Programme laufen zu lassen, d.h. Programme, deren Adressierung und Befehlssatz einem 8086/286-Protected oder 386-Protected entspricht. Machen diese Programme ausser Speicheranforderungen keine weiteren Betriebssystemaufrufe, dann laufen sie innerhalb des 64-Bit-Betriebsystems ohne weitere Vorrichtungen. Die meisten Programme machen aber Betriebssystemaufrufe, um ans Dateisystem oder an die API zu kommen. Dazu braucht es dann einen Layer, der diese Aufrufe von der alten API mit 32-Bit-Adressierung in die neue mit 64-Bit-Adressierung übersetzt. Linux 9.0 und die erste Version von WindowsXP für AMD64 haben solche Layer für 32-Bit-Programme, jedoch nicht für 16-Bit, also Real- oder 286-Protected-Mode-Programme. Bei Linux ist das Fehlen (fast) trivial: Es gab nie ein 8086- oder 80286-Linux. Bei Windows wird sich zeigen, wie einfach oder schwierig es ist, die NTVDM (der 16-Bit-Layer für WindowsNT) bei Bedarf vorzuschalten, um mit diesem doppelten Layer die Übersetzung 16 Bit nach 64 Bit zu schaffen. AMD64: Wieviel Adressraum gibt's denn nun eigentlich?In den Programmen im 64-Bit-Modus sind die Pointer 64 Bit breit, die virtuellen Adressen allerdings nur 48 Bit. Sie werden in 4 mal 9 Bit Zeiger auf eine 4-Level-Page-Table-Struktur und 12 Bit Page-Offset aufgeteilt. Insgesamt kann ein Task damit 256 TB Speicher ansprechen, alle zusammen haben einen technischen Adressraum von 16 EB. Das RAM ist bei den derzeitigen Prozessoren mit 40 Bit angebunden. Das dürfte auch reichen: Um 1 TB Speicher zusammenzubekommen, müsste man 512 2GB-Module implementieren, was Kosten in der Höhe von einer halben Million Dollar verursachen würde. 1 TB virtueller Speicher ist allerdings gar nicht mehr so illusorisch; schliesslich kostet ein Array aus drei 400 GB-Platten Mitte 2004 gerade mal um die 1000 Dollar. Brüche Die nächsten Brüche sind also bei AMD64 noch weit: Sollte der Adressraum von 1 TB nicht mehr ausreichen, braucht AMD nur ein paar Beinchen mehr an den Prozessor zu hängen, am Betriebssystem oder gar den Programmen müsste man nichts ändern. Reichen die 256 TB virtuelle Adressierung nicht mehr aus, müsste man das Betriebssystem updaten, in der Art, wie jetzt das SP2 für WindowsXP herauskommt. Für die Programme wären keine Änderungen notwendig. Die kämen erst, wenn dann auch die 64 Bit-Pointer nicht mehr reichten. Dann geht's mit XMS für 64-Bit los...;-) Die Grenze von 16 ExaByte und das 64-Bit-XMS dürften nur noch die jüngere heutige Generation erleben: Bei linearer Fortschreibung in ca. 50 Jahren. ÜbergängeMan sieht: Technisch spielt sich heute am Übergang vom 32-Bit ins 64-Bit-Zeitalter Ähnliches ab, wie einstmals beim Übergang vom 16- ins 32-Bit-Zeitalter. Doch aus verschiedensten Gründen bleibt der Programmierer von den Auswirkungen viel stärker abgeschottet, als vor 15 Jahren:
Eine gewisse Herausforderung schien mir Anfang 2000 der Übergang für Linux darzustellen. Für abwärtsinkompatible Prozessoren wie den Itanium gilt: Solange die Linux-Gemeinde nicht eine Virtual Machine für 32-Bit-Linux auf die Beine stellt, wird sich die Linux-Programme-Welt in zwei Teile spalten: In 32-Bit-Linux und 64-Bit-Linux. Aber erstens reduziert die ADM64-Architektur dieses Problem auf die Erstellung eines entsprechenden Layers - und das ist wohl schon erfolgreich geglückt. Und zweitens wird Linux die Open Source-Philosophie entgegenkommen: Kaum ein liebgewonnenes Utility, für das nicht die Source gleich mitgeliefert wird, so dass für eingefleischte "Pinguins" bei der Anschaffung einer 64-Bit-Maschine im schlechtesten Fall Neukompilieren auf dem Tagesplan stehen, aber sie nicht wirklich auf ihre Schätze verzichten müssen, die nicht ohnehin schon als 64-Bit-Binaries auf den Distributionen-CDs oder im Internet zu finden sind. Beim Übergang von 32 nach 64 Bit kein Problem. Dann wiederum an die Geschichte zurück gefragt: Warum hat es von 16 nach 32 Bit soviel Probleme gegegen? Warum wurde nicht die gleiche Methode angewandt wie heute: Emulation? Ganz einfach: Nicht nur die Größenordnung an Speicherplatz ist in den letzten Dekaden angestiegen, sondern auch die Größenordnung an Rechenleistung. Ein Emulator frisst beides: Speicherplatz und Rechenzeit. Während dieser Verbrauch heute allerdings unter 5 Prozent der Maschinenleistung liegt, waren es auf einem 8088 eher 50 Prozent oder mehr. 1981 die Rechenleistung eines teueren PC mit einem CP/M-Emulator so herunterzubremsen, dass die Maschine langsamer schlich als das 8-Bit-Konkurrenzprodukt, das war keine ernstzunehmende Alternative. Es gibt aber noch einen weiteren Unterschied zwischen 2001 und 1981: 1981 war der Speicherplatz, den der maximale Adressraum zur Verfügung stellte, einfach knapp. Die Programmierer waren Künstler darin, Bytes und Bits einzusparen (siehe TP 1.0) und programmierten oft deshalb in Assembler. Und trotzdem waren 64K damals ein enges Korsett. Das kann man heute über 4 GB nicht sagen. Genauer gesagt wissen die Programmierer eigentlich nicht so recht, wie sie 128 MB sinnvoll füllen sollen. Manchmal habe ich das Gefühl, da wird absichtlich erstmal blind Speicher alloziiert, den das Programm in Endeffekt gar nicht braucht. Es ist ja kein Problem, ein Programm mit einem Stack von 10 MB auszustatten und die entsprechende Compileroptimierung auszuschalten, so daß tatsächlich 10 MB reserviert werden, obwohl das Proggy mit 1 MB auch ausgekommen wäre. Da werden komplette Bibliotheken doppelt und dreifach gelinkt, so daß eine simple Icon-Leiste (z.B. Office-Leiste) auf 4 MB anschwillt. (Das ist der komplette Umfang von MS Word 5.0 für DOS!) Wirklich knapp wird's vielleicht hier und da im Multimedia-Bereich. Und Spiele kriegen noch jeden Hauptspeicher voll. Aber auch hier reicht nicht einmal die Phantasie, sich vorzustellen, wie man 4 GB sinnvoll füllen könnte, geschweige denn, wie sie zu knapp werden könnten. Oder umgekehrt formuliert: Hätten wir heute ein 64 MB-Limit, könnte m.E. noch soviel speicheroptimiert werden, daß erst um 2005 herum die Softwareentwicklung ernsthaft gebremst würde. Und wenn die Bremswirkung einer 4 GB (64 GB)-Grenze einsetzen würde, wird es 32-Bit-Software nur noch auf ausrangierten PCs in verstaubten Kellern geben. Doch: Wird dann auch das 64K-Limit völlig verschwunden sein? Nachtrag April 2019Nun sind schon wieder fast 20 Jahre vergangen, seitdem dieser Text entstand. Subjektiv ist die Computerentwicklung seit 2002 in vielen Bereichen fast stehengeblieben, wenn man sie mit den Entwicklung zwischen 1982 und 2002 vergleicht. In 2002 hatte man schon Windows 2000, Linux, Internet, das 64-Bit-Zeitalter war gerade am Heranbrechen, das Arbeiten als Programmierer und Anwender war zum heutigen Arbeiten sehr ähnlich. Es ist alles seitdem noch etwas mächtiger, fotorealistischer, perfekter und schneller geworden, aber das sind nur noch graduelle Unterschiede. Ich persönlich habe inzwischen beruflich gewöhnlich Rechner mit 16 GB RAM, hier privat steht sogar ein PC mit 32 GB RAM, aber bemerkbar macht sich das weniger in der Frage, ob etwas gar nicht läuft, sondern eher in der Frage, ob es schnell oder langsam läuft. Der Grund, warum ich gerade jetzt noch eine Bemerkung hier schreibe, ist, dass HP vor einigen Monaten eine aus Hauptspeicher-Sicht interessante Workstation auf den Markt gebracht hat: Für etwas mehr als 200.000$ bekommt man hier einen Rechner zum Unter-den-Schreibtisch-stellen, der mal kurz eben 3 TB RAM mitbringt. Wozu man das braucht? Sehr schwer zu sagen in einem Zeitalter, in dem es rasend schnelle SSDs gibt und daher viele Massenberechnungen per Streaming durchgeführt werden können. Vielleicht ist das auch die falsche Frage. Jedenfalls bringt dieser Rechner seit langem mal wieder mehr RAM mit als Windows (10 Pro) adressieren kann: Hier liegt das Maximum derzeit bei 2 TB. Also eine ähnliche Situation wie mit einem Rechner mit 1,5 MB RAM, der MS-DOS installiert hat. Möglich macht es der Spezial-Xeon-Prozessor 8160M (ca. 8000$ pro Stück, 24 Cores), der 1,5 TB adressieren kann plus die insgesamt 24 RAM-Slots, von denen jeder das modernste 128 GB-Modul aufnehmen kann. Unter Linux kann man die Maschine problemlos mit vollem RAM betreiben - Dank der Tatsache, dass Linux auch für High Performance Computing eingesetzt wird, ist hier erst bei 128 TB RAM Schluss. Davor würde allerdings aktuell das UEFI (Boot-System, früher BIOS) schon bei 16 TB einen Riegel vorschieben. Die Maschine ist allerdings ein starker Ausreisser nach oben. Aktuell sind nur die leistungsstärkeren Maschinen mit 16 GB RAM ausgestattet, 32 oder 64 GB sind noch eher exotisch. Nachdem im Jahr 2005 bei leistungsstärkeren Maschinen 1 GB RAM üblich war (2^30) und wir jetzt nach 12 Jahren bei 16 GB angekommen sind (2^34), legten wir in den letzten Jahren ca. 0,33 Zweierpotenzen pro Jahr RAM-Wachstum zurück. (In den 20 Jahren zwischen 1982 und 2002 hatten wir ein Wachstum von ca. 0,65 Zweierpoztenzen). In den nächsten 10 Jahren werden wir also bei ca. 2^37 = 128 GB RAM angekommen sein. Allerdings wird die Gesamtsituation auch nicht mehr vergeichbar sein, da der PC inzwischen viel mehr Speicherschichten aufweist als früher: Solange keine völlig neuen Anwendungsfälle kommen, die den RAM-Bedarf drastisch nach oben drücken, wird das RAM-Thema immer weiter im Hintergrund verschwinden - warum auch nicht? Literatur zum ThemaMatthias Withopf:UltrAWEit Wie Linux und Windows bislang mit großem Speicher umgehen c't 13/01, Seite 147 Andreas Stiller Speicherschieber Vom mühevollen Weg der Daten zwischen Prozessor und Speicher c't 3/00, Seite 260 Links zum ThemaOverview of Memory-Management Functionality in MS-DOS (Q95555) |