

|
|
|
Weiter vorne haben wir Texte, d.h. Strings in Dateien geschrieben. Gewöhnlich enthalten Strings nur ASCII-Zeichen, also Zeichen, die mit Zahlen zwischen 32 und 127. Was in Wirklichkeit in die Datei geschrieben wird, sind diese Zahlenwerte. Dies können Sie leicht überprüfen, und zwar mit einem s.g. Hex-Editor. Den werden wir im Folgenden zur Kontrolle des öfteren brauchen.
Ein Hex-Editor ist ein Editor, der die Zahlenwerte einer Datei nicht als Zeichen anzeigt (was ja nur bei Textdateien sinnvoll ist), sondern als Zahlenwerte eben. Und da er das meist im Hexadezimalsystem macht, nennt er sich Hex-Editor. Einen solchen Editor (bzw. Lister) finden Sie oft im Verbund mit komfortablen Editoren oder Dateimanagern. Ich empfehle Ihnen, den Totalcommander herunterladen, ein nicht ganz kostenloser, aber sehr günstiger und mächtiger Dateimanager. Sie müssen ihn nicht gleich bezahlen; er erinnert Sie lediglich bei jedem Programmstart daran. Wenn Sie ihn öffnen, haben Sie zwei Verzeichnisse vor sich. Wenn Sie auf eine Datei gehen und dann "F3" drücken, dann erhalten Sie eine Ansicht der Datei in einem Lister. Und wenn Sie nun hier im Menü auf "optionen" und "Hexadezimal" gehen, dann sehen Sie etwas, das so aussieht:

Ganz links vor dem Doppelpunkt ist die Adresse (Byteposition) im File angegeben. Jede Zeile umfasst in der Anzeige 16 Bytes. In der Mitte jeder Zeile werden die Zahlenwerte der 16 Bytes angegeben. Ganz rechts sieht man eine Zeichendarstellung der Bytes.
Auf diese Weise können wir im Folgenden auch dann in eine Datei "hineinschauen" und kontrollieren, was wir gemacht haben, wenn die Datei mit einem Texteditor nicht lesbar ist. Am Ende dieses Kapitels sind wir in der Lage, unseren eigenen Hex-Editor zu schreiben!
Echte binäre Dateien enthalten nicht nur Bytes zwischen 32 und 127, sondern alle Werte zwischen 0 und 255. Schon mit den bisher kennengelernten Mitteln sollte es eigentlich kein Problem sein, solche beliebigen Bytes zu schreiben. Mit der CHR$-Funktion können wir ja jede Zahl zwischen 0 und 255 in ein Char, ein logisches (wenn auch vielleicht nicht lesbares) "Zeichen" verwandeln. Entsprechend enthält das Programm
OPEN "a.dat" FOR OUTPUT AS #1
FOR i = 0 TO 255
FOR j = 0 TO 255
PRINT #1, CHR$(j);
NEXT j
NEXT i
CLOSE 1
auch keine grossen Überraschungen. Wir schreiben einfach 256 mal alle Bytes zwischen 0 und 255 hintereinander in ein File. Das Semikolon am Ende der PRINT-Anweisung verhindert, dass uns eine Return-Sequenz (Hex 0D0A) dazwischen rutscht.
Hat das funktioniert? Schauen Sie sich's mit dem Hex-Editor an!
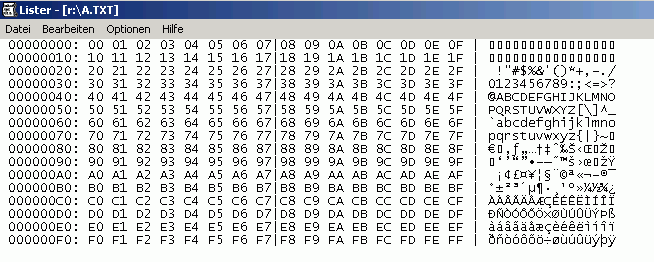
Sieht ganz gut aus.
Zur Kontrolle wollen wir das wieder einlesen. Aber wie? Klar, wir öffnen ein File zum Lesen ("FOR INPUT AS..."). Aber mit welcher Anweisung lesen wir die Bytes ein? INPUT? Dann bräuchten wir so etwas wie Zeilen. Aber die gibt es ja hier nicht.
Hier lernen wir eine neue Funktion kennen: INPUT$. Syntax:
INPUT$(n[,[#]Dateinummer%])
| n | Die Anzahl der zu lesenden Zeichen (Byte). |
| Dateinummer | Die Nummer einer geöffneten Datei. Wenn Dateinummer weggelassen wird, liest INPUT$ von der Tastatur. |
Mit der INPUT$-Funktion können wir also einfach eine feste Anzahl Bytes einlesen. INPUT$(200,1) heisst: "Gib' mir die nächsten 200 Zeichen aus Datei 1." Ideal für unseren Zweck.
Überlegen Sie sich nun ein Programm, mit dem Sie alle 64K, die wir gerade rausgeschrieben haben, wieder einlesen!
Aber ärgern Sie sich nicht, wenn Sie dabei über die Meldung "Eingabe nach Dateiende" stolpern! Sondern lesen Sie gleich hier weiter:
Schauen wir diese Variante an:
OPEN "a.dat" FOR INPUT AS #1
OPEN "b.dat" FOR OUTPUT AS #2
FOR i = 0 TO 255
a$ = INPUT$(256, 1)
FOR j = 0 TO 255
k1$ = MID$(a$, j + 1, 1)
k = ASC(k1$)
PRINT #2, i, j, k
NEXT j
NEXT i
Beim INPUT$ hagelt's die oben beschriebene Laufzeitfehlermeldung. Was heisst das? Nun, ganz einfach: Jede Datei hat am Ende ein spezielles Byte, das markiert, dass hier die Datei zuende ist. Wir haben ja schon die Funktion EOF() kennengelernt. Sie tut nichts anderes, als achtgeben darauf, ob dieses spezielle Byte gerade eingelesen wurde. Wenn ja, dann gibt sie TRUE zurück. Wir nennen das Byte daher EOF-Byte. Es handelt sich um den Wert Hex 1A, Dez 26. Wenn nun die Ausführung von INPUT$ das 27. Bytes ausliest, dann erkennt es den EOF-Marker. INPUT$ gibt aber die Anweisung, noch weitere Bytes auszulesen, also HINTER dem EOF-Zeichen. Und das ist natürlich verboten. Es sei denn, wir können dem Programm sagen: "Hör mal, liebes Programm, es GIBT KEIN EOF-Zeichen! Es gibt überhaupt keine besonderen Steuerzeichen. Vergiss es!" Und das machen wir, indem wir die Datei im BINARY-Modus öffnen:
OPEN "a.dat" FOR BINARY AS #1
Und schon funktioniert es und wir können eine makellose Liste in der Datei b.dat abrufen!
Ein Beispiel sind Grafikdateien. Wir können Grafiken nicht nur auf dem Bildschirm erzeugen, sondern auch in eine Datei schreiben. Der Vorteil davon ist, dass wir in der Grösse und Farbtiefe der Datei nicht beschränkt sind. Sie wollen ein 3000x3000 Punkte-Fraktal erzeugen? Kein Problem! Schreiben Sie die entsprechenden binären Daten in eine Grafikdatei und betrachten Sie anschliessend diese Datei mit einem Bildbetrachter.
Dazu muss man natürlich das spezielle Format der Grafikdatei kennen. Es gibt verschiedene Formate, je nach Kompressionsart. Das einfachste Format ist natürlich das ganz ohne Kompression, das bmp-Format. Das wollte ich in diesem Kapitel auch zu Demo-Zwecken behandeln, bin aber bisher nicht dazu gekommen. Macht nichts: In Teil III beschäftigen wir uns noch ausführlich damit.
"Random Access" heisst nicht "zufälliger Zugriff", sondern "wahlfreier Zugriff", man könnte auch sagen: "Gezielter Zugriff". Es ist das Gegenteil von sequentiellem Zugriff, bei dem immer nur das gerade gelesen werden, was gerade als Nächstes kommt. Beim sequentiellen Zugriff muss man sich die Datei vorstellen wie ein Tonband. Es gibt einen Dateizeiger. Dieser spielt die Rolle des Tonkopfes. Beim Lesen oder Schreiben wird immer ein kleines Stück gelesen, dann rückt der "Tonkopf", also der Dateizeiger vorwärts. Die einzige Beeinflussung auf die Position des Dateizeigers, des "Tonkopfes", können wir dadurch ausüben, dass wir die Datei schliessen und wieder öffnen und damit den Dateizeiger auf den Anfang der Datei verschieben.
Bei Random Access sieht das anders aus: Hier können wir den Dateizeiger auf jedes Byte in der Datei schieben. Wir können also im Grunde auf die Datei genauso zugreifen wie auf den Hauptspeicher. Dazu müssen wir nur sagen, bei welcher Adresse wir ein Byte aus der Datei lesen oder an welche Adresse wir ein Byte in die Datei schreiben wollen. Und wir müssen höllisch aufpassen, dass die Adresse nicht ausserhalb des Files liegt, also vor Beginn oder nach dem Ende der Datei!
Wenn wir byteweise auf eine Datei zugreifen wollen, müssen wir uns das Ganze wie den Zugriff auf einen Arbeitsspeicher vorstellen. Und damit man auf einen solchen Speicher zugreifen kann, muss er physisch erst einmal existieren: Wir müssen die Datei ersteinmal erstellen. Das machen wir am Besten mit dem altbekannten OPEN FOR OUTPUT-Befehl. Dann schreiben wir eine Anzahl Bytes. Und schliessen die Datei wieder. Diese Datei stellt nun unser "Arbeitsspeicher" da. Man bezeichnet so einen ausgelagerten Speicher übrigens als "Swap"-Speicher oder einfach als "Swap".
Um byteweise auf die Swap-Datei zuzugreifen, benutzen wir die Befehle GET und PUT und den Zugriffsmodus BINARY: OPEN
Bei GET ist es entsprechend, nur dass
So, nun ein kleines Beispielprogramm:
OPEN "R:\a.txt" FOR OUTPUT AS #1 FOR i = 0 TO 255 a$ = CHR$(i) PRINT #1, a$; NEXT i CLOSE (1) OPEN "R:\a.txt" FOR BINARY AS #1 FOR i = 1 TO 25 j = i * 10 GET #1, j + 1, a$ PRINT j, ASC(a$) NEXT i CLOSE (1)
Dieses Progrämmchen schreibt wie vorhin 256 Bytes in die Swap-Datei. Dann wird diese binär geöffnet und wir lesen nun von jeder 10. Adresse ein Byte aus.
In der modernen Software-Entwicklung haben Swap-Dateien nicht mehr so grosse Bedeutung wie früher, da es ja locker möglich ist, viele hundert Megabyte im Hauptspeicher zu halten. Aber es gibt sie schon noch: In der Messdatenverarbeitung und Statistik oder in der Video- und Audiobearbeitung.
QBasic selbst erlaubt nur die Verwendung von bis zu 160K Hauptspeicher und jede Variable, also jedes Array oder jeder String darf nur maximal 64K gross werden. In Spielen werden aber oft viele Grafiken gebraucht, insbesondere oft s.g. "Maps", Landkarten, auf denen sich der Spieler bewegen kann. Der Spieler sieht immer nur einen Ausschnitt, den er dann über die eigentliche Karte bewegt. Die Karte selbst kann viele Tausend mal viele Tausend Pixel enthalten. Es ist nun problemlos möglich, diese Map in einer Swap-Datei zu speichern und mittels GET und PUT immer genau den Bildausschnitt in den Hauptspeicher zu laden, den der Spieler gerade sieht. Wir wollen das hier nicht weiter verfolgen, aber die folgende Variante des obigen Beispielprogrämmchens zeigt, wie man mit QBASIC eine 4 MB grosse Swap-Datei erstellen und benutzen kann:
DIM i AS LONG OPEN "R:\a.txt" FOR OUTPUT AS #1 FOR i& = 0 TO 4* 1024& * 1024-1 a$ = CHR$(RND(255)) PRINT #1, a$; NEXT i CLOSE (1) OPEN "R:\a.txt" FOR BINARY AS #1 FOR i = 1 TO 25 j = i * 10 GET #1, j + 1, a$ PRINT j, ASC(a$) NEXT i CLOSE (1)
Das Besondere an dem Progrämmchens ist die erste Zeile mit dem "DIM" und die "&"-Zeichen hinter den Zahlen in der dritten Zeile. Nun, beides sorgt dafür, dass für die Variable i nicht nur 2 Bytes Speicher vorgesehen werden, sondern 4 Bytes, was dann einen Zahlenraum von 0 bis rund 4 Mrd. (4 GB) erlaubt und nicht nur 0 bis 65000, also 0 bis 64K. Wir werden auf diese "Typen" und "Deklarationen" später noch ausführlich zu sprechen kommen.
Wir waren das Problem schon einmal weiter vorne angegangen: Als wir im vorigen Kapitel dem "schnellen Zeilenmanagement" begegneten: Wie schreibe ich einen Editor, der schnell zwischen die 2000. und 2001. Zeile noch eine einfügen kann? Und dabei nicht Megabyteweise Daten verschieben muss? Die Antwort war: Wir brauchen einen Index, der Zeiger auf jede Zeile enthält. Damals waren die Zeiger Indizes eines Arrays. Jetzt können wir als Zeiger die Byteposition in einer Datei hernehmen. Die Zeiger sammeln wir in einem eigenen Array, dem Index. Hier können wir nachschauen, an welcher Byteposition Zeile 0,1,7 oder 134 beginnt. Die folgende Grafik zeigt das Schema.

Auf diese Art und Weise können wir leicht einen Editor schreiben, der so grosse Texte verwaltet wie der Hauptspeicher gross ist! Machen Sie sich ans Werk!