

|
|
|
Haben Sie inzwischen auch schon Ihr erstes grösseres Projekt? An dem Sie schon seit einem Jahr oder länger arbeiten und an dem Sie immer wieder hier etwas erweitern und dort noch etwas verschönern? Oder haben Sie vielleicht schon zwei oder drei solcher Projekte? Die Sie für mindestens ein paar Monate beschäftigen und bei denen sich schon ein paar Tausend Zeilen Code angesammelt haben? In diesem Kapitel werden wir darauf zu sprechen kommen, wie man ständigen Ärger im Code-Chaos vermeiden und sich seinen eigenen Code-Schatz aufbauen kann.
Diese Sicht ist gleichzeitig die aktive Sicht auf das Thema "Bibliotheken", denn sie sind dabei das zentrale Werkzeug. Eigene Bibliotheken zu bauen und zu benutzen ist allerdings das eine. Das andere und vielleicht im Moment fast drängendere: Die Bibliotheken anderer zu nutzen. Dies zu lernen ist die Grundvoraussetzung für die kommenden Kapitel, in denen es darum geht, die eigenen Möglichkeiten mit ihrer Hilfe gewaltig zu erweitern.
Wir haben ja schon am Anfang dieses Teils über die drei Möglichkeiten gesprochen, Routinen in externe Dateien auszulagen:
Eine interessante Frage ist: Wann benutze ich was? Diese Frage kann man nicht generell beantworten. Jeder findet da mit der Zeit sein eigenes Rezept. Aber es gibt einige Aspekte, die zu beachten vielleicht ganz nützlich ist:
Der grosse Vorteil, die eigenen Routinen im Sourcecode zu halten: Man kann jederzeit alles verändern, ohne sich Sorgen darüber machen zu müssen, dass irgendetwas veraltetes ins Programm eingebunden wird oder diesen Sorgen mit einem komplizierten Projektmanager begegnen zu müssen. Die beiden Nachteile: Die Routinen sind nur für das eigene Entwicklungssystem zugänglich. Und es kostet Compilierzeit. Sofern beide Nachteile nicht bemerkbar werden, sollten Sie sich des genannten Vorteils nicht berauben.
Grundsätzlich fängt der Aufbau eigener Bibliotheken meist damit an, dass Sie sich dabei ertappen, wie Sie Routinen von einem Programm ins nächste kopieren. An diesem Punkt fange ich immer damit an, zu sagen: "Jetzt wird's Zeit für eine toollib". Die heisst dann einfach "tool" und da rein kommen alle Routinen, die versprechen, allgemeiner nutzbar zu sein: String-Manipulationsroutinen, kleine allgemeine Umrechnungen, kleine Statistikfunktionen u.v.m.. Später werden Sie Routinen bemerken, die zwar für das Projekt spezifisch sind, dort aber an verschiedenen Stellen gebraucht werden. Also empfiehlt es sich vielleicht, wenn das Projekt "foo" heisst, diese Routinen in eine Datei "footool" auszulagern. Wieder später stellen Sie fest, dass es Sinn machen würde, das inzwischen riesige footool thematisch zu unterteilen: Grafische Sachen in eine Datei, Datenbankroutinen in die nächste usw. Und schon haben wir "foograph", "foobase" usw. Und so kommen mit der Zeit verschiedene Sammlungen zustande.
Eine Grundregel beim Aufbau von Projekten lautet: Gib dem Compiler Informationen zum frühest möglichen Zeitpunkt! Denn sonst beraubt man sich selbst wichtiger Möglichkeiten. Ein Beispiel sind Referenzbeziehungen zwischen Klassen. Je mehr solche Referenzen (Zeiger) da sind, desto mehr Möglichkeiten habe ich, die Daten trotz einer ausgefeilten Struktur (und damit Zugangsbeschränkungen) zu beherrschen. Nun betrachten wir einmal zwei Möglichkeiten, unser Progamm aufzubauen. Wir machen das anhand der angedeuteten Skizze einer Physiksimulation, in der sich Teilchen in Feldern bewegen sollen:
Möglichkeit 1: Eins nach dem andernCONST Cc1_charge=0 CONST Cc1_mass=1 CONST Cc1_surface=2 type tparticle DIM AS DOUBLE PROPERTY(3) END type 'Dieser Header funktioniert nicht: SUB tparticle_move(p AS tparticle PTR, FIELD AS tfield ptr) ... ' Bewege das Teilchen im Feld 'Hier müsste ich Informationen über tfield haben. Kann ich aber nicht haben, da 'die Deklaration von tfield und die zugehörigen Konstanten usw. noch gar nicht bekannt sind. END SUB CONST Cc2_const=0 CONST Cc2_form=1 type tfield ... END type SUB tfield_force(f AS tfield PTR, p AS tparticle ptr) 'Gibt die Kraft zurueck, die ein Teilchen im Feld erfährt. END SUBMöglichkeit 2: Informationen so früh wie möglich:
' Konstanten deklarieren sobald als möglich: CONST Cc1_charge=0 CONST Cc1_mass=1 CONST Cc1_surface=2 CONST Cc2_const=0 CONST Cc2_form=1 ' Typen deklarieren sobald als möglich: type tparticle DIM AS DOUBLE PROPERTY(3) END type type tfield ... END type ' Header deklarieren sobald als möglich: DECLARE SUB tparticle_move(p AS tparticle PTR, FIELD AS tfield ptr) DECLARE SUB tfield_force(f AS tfield PTR, p AS tparticle ptr) 'Hier funktioniert der Header: SUB tparticle_move(p AS tparticle PTR, FIELD AS tfield ptr) ... ' und man kann hier sogar tfield_force() aufrufen! END SUB SUB tfield_force(f AS tfield PTR, p AS tparticle ptr) 'Gibt die Kraft zurueck, die ein Teilchen im Feld erfährt. ' und man kann hier auch tparticle_move() aufrufen! END SUB
Also: Auch wenn es beim Programmieren bequem erscheinen mag, alles zu einer Klasse an einem Ort in einer Datei zu haben - es beschneidet die Möglichkeiten enorm. Die Regel lautet hingegen:
|
1. bis 4. kommen in eine eigene Datei, eine s.g. Header-Datei, da hier fast nur Header, also Deklarationen stehen. Und eben die Definitionen der Typen. In Freebasic bekommen sie die Endung "*.bi". In C/C++ haben sie die Endung "*.h". Man spricht in diesem Zusammenhang in Anlehnung an PASCAL/Delphi auch manchmal von "Interface"-Dateien, da sie einem Programm, das sie einbindet, das "Interface" der Klassen und Funktionen bekannt geben.
Wenn Sie sich die mit Freebasic mitgelieferten Headerdateien zu den Bibliotheken ansehen, werden Sie genau dieses Prinzip erkennen.
Eingebunden werden Sourcecode-Dateien im allgemeinen mittels des #include-Befehls:
#INCLUDE "hallo.bi" #INCLUDE "hallo.bas" PRINT hallo()
Das # am Anfang zeigt an, dass es sich um einen s.g. Präprozessor-Befehl handelt. Bevor der Compiler irgendetwas anderes macht, schaut er sich die #-Befehle an und führt erstmal diese aus. Das heisst, er bindet an dieser Stelle den entsprechenden Quelltext ein. Erst dann beginnt seine eigentliche Arbeit und in dieser sieht er die #-Befehle dann gar nicht mehr, sondern nur noch BASIC. #-Befehle steuern also die Zusammensetzung des Quellcodes, nicht seinen Inhalt. Sie werden verwendet, um die Zusammensetzung des Quellcodes zu verwalten, z.B. ihn für verschiedene Compilerversionen "mundgerecht" zu machen oder um die richtigen Headerdateien und Module einzubinden (siehe unten) usw.
Wenn wir Routinen und Klassen zu einem Thema zusammenlegen und dann in zwei Dateien "foo.bas" und "foo.bi" abspeichern, dann nennen wir das ein "Modul". Wir werden nur dann von einer "Bibliothek" oder "Lib" sprechen, wenn das Modul einen etwas allgemeinern Nutzen hat. Ist es dagegen nur innerhalb des Hauptprogramms zu gebrauchen, dann ist es eben ein Modul des Hauptprogramms.
Die Strukur von Projekten sieht also im allgemeinen so aus:
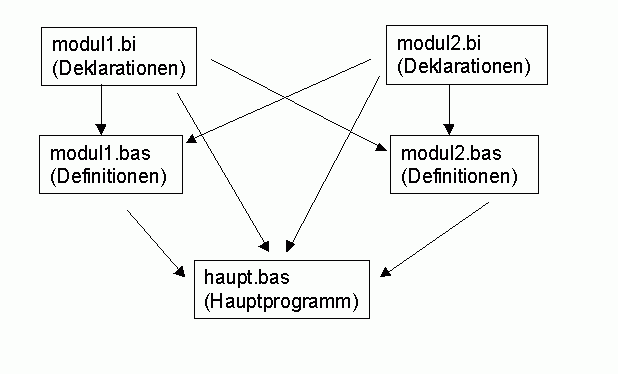
Das heisst, modul1.bas bindet beide Headerdateien modul1.bi und modul2.bi ein. modul2.bas genauso und haupt.bas sowieso. Dann ist gewährleistet, dass die entsprechenden Routinen in modul1.bas und modul2.bas zu jedem Zeitpunkt alle Deklarationen kennen - und nicht nur die des eigenen Moduls.
Nun gibt es ein Problem. Welche Module binden welche Headerdateien ein? Es würde ja z.B. theoretisch reichen, wenn "haupt.bas" nur die beiden Module "modul1.bas" und "modul2.bas" einbinden würde, da diese selbst ja jeweils ihre eigenen Headerdateien einbinden und damit die Header auch automatisch in "haupt.bas" zur Verfügung stehen. Aber nehmen wir an, es gäbe noch ein Modul "abc.bas", das wir in "haupt.bas" benötigen. Wird "abc.bas" nun schon durch eines der anderen Module eingebunden oder nicht? Wenn ja: Dann meckert der Compiler, dass da Typen und Konstanten doppelt definiert werden. Das mag er gar nicht. Es wäre sehr umständlich, dies jedes Mal nachforschen zu müssen. Ausserdem fehleranfällig: Vielleicht spielen wir einmal eine neue Version des Moduls ein, das früher "abc.bas" einband - und es in der neuen Version nicht mehr tut. Und schon haben wir ein Problem.
Um dieser mühsamen include-Verwaltung von Hand aus dem Weg zu gehen, gibt es #define und #ifdef. Mit #define können wir für den Compiler selbst eine Konstante definieren.
#define COMPVERSION 0.17 ? COMPVERSION sleep
Hier trennt also Name und Definitionswert ein Leerzeichen, kein Gleichheitszeichen. Diese Konstante wird beim Preprocessing in den Quellcode eingesetzt. Es gibt auch die Möglichkeit, keinen Wert anzugeben:
#define MYPROG
Dann kann man hinterher abfragen, ob MYPROG definiert ist oder nicht.
Bemerkung zur Nutzung von #define
Eine Arbeit gelingt nur dann, wenn man das richtige Werkzeug für den richtigen Zweck benutzt. #define hat nur zwei Zwecke: Die Steuerung der Quellcodezusammensetzung und s.g. Makros. (Makros halte ich für verzichtbar und behandle sie hier nicht.) #define hat jedenfalls nicht den Zweck, Bestandteil des Quellcodes zu sein. Schreibe ich z.B. ein Buchhaltungsprogramm, so gehört der Mehrwertsteuersatz in eine CONST-Konstante, nicht in ein #define. Das hat mehrere Gründe:
Zurück zum Problem: Wir können nun mit #define registrieren, ob eine Datei bereits eingebunden ist oder nicht, indem wir in ihr einfach eine #define-Konstante definieren und diese später mit #ifdef (bzw. ifndef) abfragen:
'modul1.bi #define modul1.bi DIM SHARED AS INTEGER i1 DECLARE FUNCTION foo() AS INTEGER ----------------- 'modul2.bi #define modul2.bi #ifndef modul1.bi #INCLUDE "modul1.bi" #endif DIM SHARED AS INTEGER i2 ----------------- 'modul1.bas #define modul1.bas #ifndef modul1.bi #INCLUDE "modul1.bi" #endif #ifndef modul2.bi #INCLUDE "modul2.bi" #endif FUNCTION foo() AS INTEGER i1=1 i2=2 END FUNCTION ----------------- 'haupt.bas #INCLUDE "modul1.bi" #INCLUDE "modul2.bi" #INCLUDE "modul1.bas" foo() ? i1 ? i2 SLEEP
Gehen wir ins Hauptprogramm und arbeiten den Compiliervorgang der Reihe nach ab. Zunächst: #include "modul1.bi". Dort wird am Anfang die Konstante modul1.bi definiert und dann wird der Rest eingebunden. Fein. Nun wieder im Hauptprogramm, nächstes include: #include "modul2.bi". Dort wird erstmal die Konstante modul2.bi definiert. Wenn nun nicht #ifndef käme, würde modul1.bi eingebunden - das ist aber schon eingebunden! #ifndef modul1.bi sagt: Wenn modul1.bi nicht definiert ist (ifndef = "if not defined"), dann und nur dann binde modul1.bi ein. Es könnte übrigens hier auch normaler Programmcode folgen. Der Teil, der durch das #ifndef bedingt ist, wird am Ende durch das #endif eingeklammert. Böse Fehlerquelle, falls mal eines fehlen sollte! Der Compiler kriegt ja nicht mit, was hier abgeht und bejammert nur den unmöglichen Code, der dadurch entsteht.
Und so geht's weiter: Beim Einbinden von modul1.bas wird keines der beiden Module mehr eingebunden, weil sie schon drin sind (beide #ifndef sind false). Und so ist am Ende nichts doppelt eingebunden und trotzdem alles notwendige eingebunden.
Seit Version 0.14 oder Version 0.15 gibt es eine Abkürzung für die Lösung des Problems doppelter Includes: Setzt man hinter #include das Schlüssewort "once", dann kann man sich die ganzen #defines sparen, der Compiler merkt sich, ob er die Datei schon eingebunden hat. Man muss es ihm nicht mehr sagen.
Eine statische Bibliothek ist eine Sammlung von Routinen in Maschinensprache. Diese "wartet" sozusagen darauf, von einem Hauptprogramm eingebunden zu werden. Die Aufgabe, den Maschinencode des Hauptprogramms und den der Bibliothek "zusammenzukleben", übernimmt der s.g. "Linker". Beim "Zusammenkleben" wird der Maschinencode der Bibliothek auch noch einmal leicht verändern; es werden Zeiger an das Gesamtprogramm angepasst. Daher spricht man beim Maschinencode der Bibliotheken von "Objectcode", was soviel bedeutet wie: Einbindbar, aber nicht alleine lauffähig.

Am obigen Beispiel: Zuerst wird modul1.bas zu lib1.a kompiliert. Dann modul2.bas zu lib2.a. Schliesslich haupt.bas zu haupt.a Der Suffix ".a" kennzeichnet bei FBC eine (Objectcode-)Bibliothek. haupt.bas hat keine #includes von modul1.bas und modul2.bas mehr. Damit aber der Compiler in haupt.bas überhaupt mit den Aufrufen der Routinen aus den externen Modulen (foo()) etwas anfangen kann, müssen die entsprechenden Deklarationen eingebunden sind, also modul1.bi und modul2.bi.
Im Anschluss daran wird nun der Linker beauftragt, lib1.a, lib2.a und haupt.a zu einem ausführbaren Programm haupt.exe zusammenzulinken.
Der FBC ist Compiler und Linker in einem Programm, je nach Optionen, die ihm auf der Kommandozeile mitgegeben werden. Dadurch gehört dann der einfache Aufruf fbc
Mit fbc -lib
Die ganze Gruppe aus Sourcedateien und Objectcode-Libs nennt man ein "Projekt". Ein Projekt besteht aus einzelnen Modulen, das sind die Sourcecodeteile, die zusammen kompiliert werden. "modul1.bas"+"modul1.bi" ist also ein Modul, "modul2.bas"+"modul2.bi" ein anderes. Ein Projekt mit mehreren Modulen zu verwalten, kann kompliziert werden, dann nämlich, wenn man an mehreren Modulen simultan arbeitet. Hier kann es zu einer Fehlerquelle kommen, die ziemlich ärgerlich ist und die wir bisher nicht kennengelernt haben: Man linkt eine veraltete Lib ans Hauptprogramm. Das heisst, eine, die nicht dem aktuellen Quelltext des Moduls entspricht. Man hat also vergessen, die Lib nochmal neu zu kompilieren. Das kann extrem aufwändige Suchexpeditionen nach sich ziehen. Um dies zu vermeiden, kompiliert man entweder immer alles oder man benötigt ein s.g. make-Programm, das prüft, welche Quellcodedateien neuer sind als die zugehörige Lib und diese ggf. neu kompiliert. Sich mit Freebasic ein solches make-Programm in einfacher Form selbst zu schreiben, ist nicht so schwierig.
Die einfachere Konstellation ist allerdings, dass man mit einigen vorkompilierten "Werkzeuglibs" arbeitet, die nur selten aktualisiert werden. Dann kann man auch mit FBIDE weiterarbeiten. Man schreibt in den Settings eben in die Aufrufzeile den entsprechenden Aufruf, z.B. "fbc -a tool1.a -a tool2.a %1" und das war's. Ändert man doch einmal etwas an seinen Werkzeuglibs, kann man diese von der Kommandozeile aus kompilieren.
Nach soviel Theorie probieren wir das an einem einfachen Beispiel aus:
------------------ 'modul1.bi DECLARE SUB foo1() ------------------ 'modul2.bi DECLARE SUB foo2() ------------------ 'modul1.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo1() ? "I'm foo1" END SUB ------------------ 'modul2.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo2() ? "I'm foo2" END SUB ------------------ 'haupt.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" foo1() foo2() SLEEP
Kompilieren Sie die beiden Module mit "fbc -lib modul1.bas" und "fbc -lib modul2.bas" und das Hauptprogramm mit "fbc -a libmodul1.a -a libmodul2.a haupt.bas". Es müsste funktionieren.
Es hatte seinen guten Grund, warum wir beim obigen Beispiel keine globalen Variablen verwendet haben. Variablen, die wir mit DIM SHARED ... deklariert, sind nämlich nur innerhalb eines Moduls deklariert. Man nennt sie "modulglobal". Bis jetzt war das egal, da das ganze Programm aus einem einzigen Modul bestand. Aber was jetzt, wenn wir eine Variable benötigen, die im ganzen Programm definiert ist? (Dies ist für Programmabläufe vielleicht nicht so oft notwendig, aber für das Debuggen sehr wohl: Kontrolldaten, die im ganzen Programm verfügbar sind.)
Nun, das technische Problem ist, dass der Linker von Variablendeklarationen in den Libs nichts weiss. Er weiss zwar, dass da Variablen in den Libs sind, aber was die mit den Variablen in haupt.bas zu tun haben, ist ihm unbekannt, da für ihn die Namen der Variablen nicht existieren. (In Maschinencode gibt es keine Variablennamen...). Man muss ihm also eine Hilfestellung geben. Das geschieht mit dem Befehl EXTERN. Wie man ihn benutzt, sei hier am obigen Beispiel gezeigt:
------------------ 'modul1.bi EXTERN glob1 ALIAS "glob1" AS INTEGER DECLARE SUB foo1() ------------------ 'modul2.bi DECLARE SUB foo2() ------------------ 'modul1.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" DIM SHARED AS INTEGER glob1 SUB foo1() ? "I'm foo1" glob1=1 END SUB ------------------ 'modul2.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo2() ? "I'm foo2" END SUB ------------------ 'haupt.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" foo1() foo2() ? "glob1=";glob1 SLEEP
Was haben wir gemacht? Wir haben in einen Header die Anweisung 'EXTERN glob1 alias "glob1" as integer' gesetzt. Das bedeutet: Linker, falls du auf eine Variable namens "glob1" in einem Modul triffst, dann ist das mit der Variablen zu identifizieren, die in diesem Modul glob1 heisst. Algemein: 'EXTERN var1 alias "var2" as integer' meint: Linker, falls du auf eine Variable namens "var2" in einem Modul triffst, dann ist das mit der Variablen zu identifizieren, die in diesem Modul var1 heisst.
Anschliessend ist die Variable var1 in den Modulen bekannt, die diesen Header einbinden. Deklarieren müssen/dürfen wir diese Variable nur in einem Modul, hier in modul1.bas.
Über die Anwendungsbereiche von dynamischen Libs haben wir uns oben schon Gedanken gemacht. Also hier gleich in media res: Prinzipiell funktioniert die Erzeugung genauso wie bei statischen Libs. Ein paar technische Unterschiede:
------------------ 'modul1.bi DECLARE SUB foo1 LIB "modul1" ALIAS "foo1" () ------------------ 'modul2.bi DECLARE SUB foo2 LIB "modul2" ALIAS "foo2" () ------------------ 'modul1.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo1() EXPORT ? "I'm foo1" END SUB ------------------ 'modul2.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo2() EXPORT ? "I'm foo2" END SUB ------------------ 'haupt.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" foo1() foo2() SLEEP
Heisst: Wir binden zur "Linkerzeit" die Module zusammen. Etwas widersprüchlich zum Namen "Dynamisch", aber durchaus möglich: Auch dynamische Bibliotheken können statisch gelinkt werden. Das hat dann Vorteile, wenn man über die Import-Lib verfügt (die Import-Libs zu sehr vielen "grossen" Libs wie GTK+, FMOD usw. werden mit Freebasic mitgeliefert) und den Lib-Code in die .exe miteinbinden möchte, so dass das Programm in nur einer einzigen .exe-Datei enthalten ist. Das hat was, zumal Zugriffsprobleme oder DLL-Versionsprobleme damit aus der Welt geschafft sind.
So etwas benötigen wir sehr häufig, wenn wir die DLL's von anderen Anbietern wie GTK, GLUT, FMOD etc. auf einfache Art und Weise benutzen wollen.
Das Kompilieren der .exe ist auch denkbar einfach: Solange man nicht händisch die Kompilationsergebnisse der Libs umbenennt, genügt es, haupt.bas völlig ohne Option zu kompilieren: fbc haupt.bas. Und fertig ist die haupt.exe!
Heisst: Erst zur Laufzeit sucht sich das Hauptprogramm aus den DLL's (oder SO's) seine Routinen zusammen. Das erfordert allerdings etwas Vor- und Nacharbeit:
DIM AS INTEGER modul1LIB DIM AS SUB() foo1
Den Umgang mit unterschiedlichen Headern kann man vermeiden, wenn man mittels #defines und #ifdef die unterschiedlichen Deklarationen im (gemeinsamen) Headerfile auseinanderhält.
Das Ganze am Beispiel:
--------------------------------------------- 'modul1.bi #ifdef DLLCALL DECLARE SUB foo1 LIB "modul1" ALIAS "foo1" () #else DIM SHARED AS INTEGER modul1LIB DIM SHARED AS SUB() foo1 #endif --------------------------------------------- 'modul2.bi #ifdef DLLCALL DECLARE SUB foo2 LIB "modul2" ALIAS "foo2" () #else DIM SHARED AS INTEGER modul2LIB DIM SHARED AS SUB() foo2 #endif --------------------------------------------- 'modul1.bas #define DLLCALL #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo1() EXPORT ? "I'm foo1" END SUB --------------------------------------------- 'modul2.bas #define DLLCALL #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" SUB foo2() EXPORT ? "I'm foo2" END SUB --------------------------------------------- 'haupt.bas #INCLUDE ONCE "modul1.bi" #INCLUDE ONCE "modul2.bi" modul1LIB = DYLIBLOAD( "modul1" ) IF(modul1LIB = 0 ) THEN PRINT "Cannot load the dynamic library modul1, aborting program..." SLEEP END 1 END IF modul2LIB = DYLIBLOAD( "modul2" ) IF(modul2LIB = 0 ) THEN PRINT "Cannot load the dynamic library modul2, aborting program..." SLEEP END 1 END IF foo1 = DYLIBSYMBOL(modul1LIB, "foo1" ) foo2 = DYLIBSYMBOL(modul2LIB, "foo2" ) foo1() foo2() SLEEP DYLIBFREE modul1LIB DYLIBFREE modul2LIB ---------------------------------------------
Damit haben wir solide Grundlagen zum Umgang mit Libraries. In den nächsten Kapiteln werden wir uns nun damit beschäftigen, wie man sich in fertige Libs einarbeitet.